Part 3 in our SQL Parsing Journey With TypeScript
Parsing Simple SQL Queries
How query strings become AST objects
The day for parsing has finally arrived! There were several building blocks that we needed to setup first in our library but with those out of the way we can get into pushing the language for real. If you haven’t seen the previous articles, I highly suggest taking a quick peek through them using the links above and if you already have, welcome back! Just like last time, I’ll start off with a quick sample of what we’ll be able to do at the end of this article:
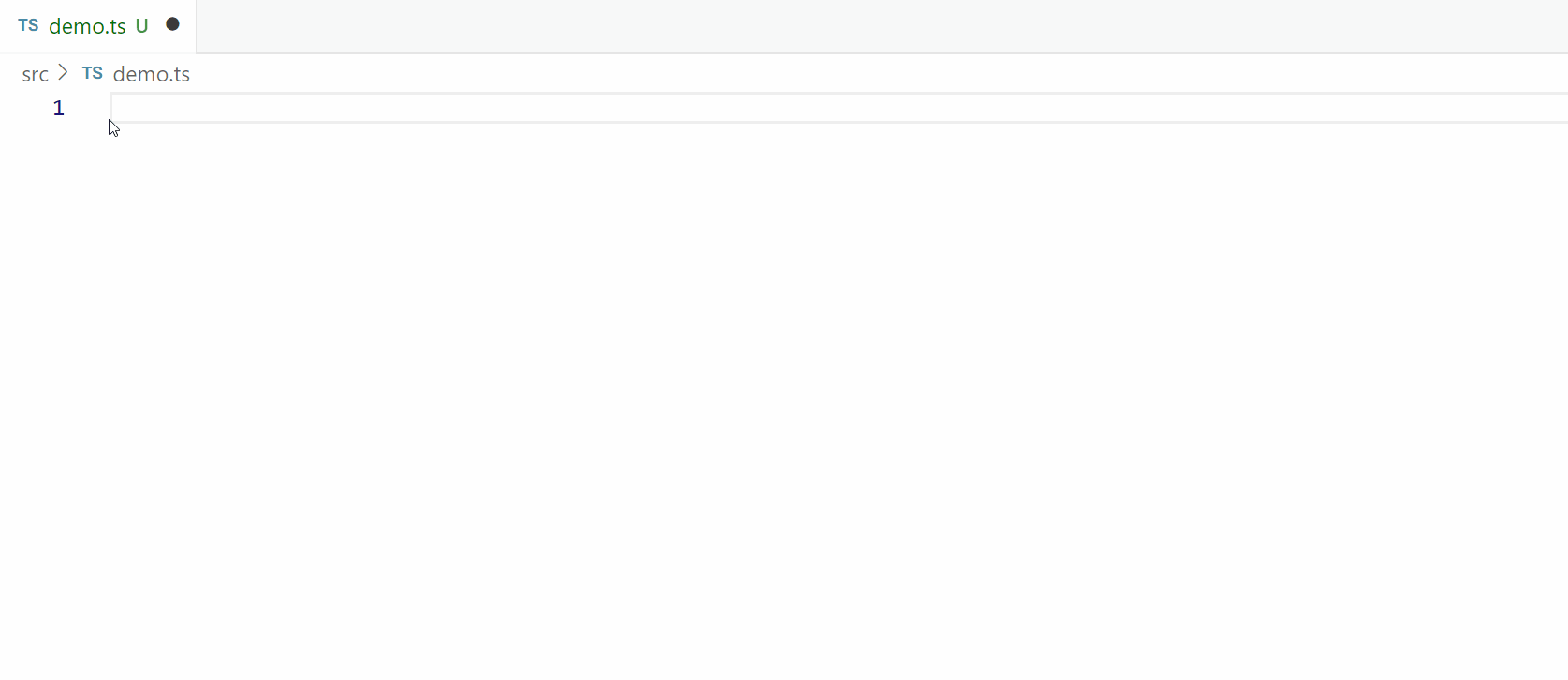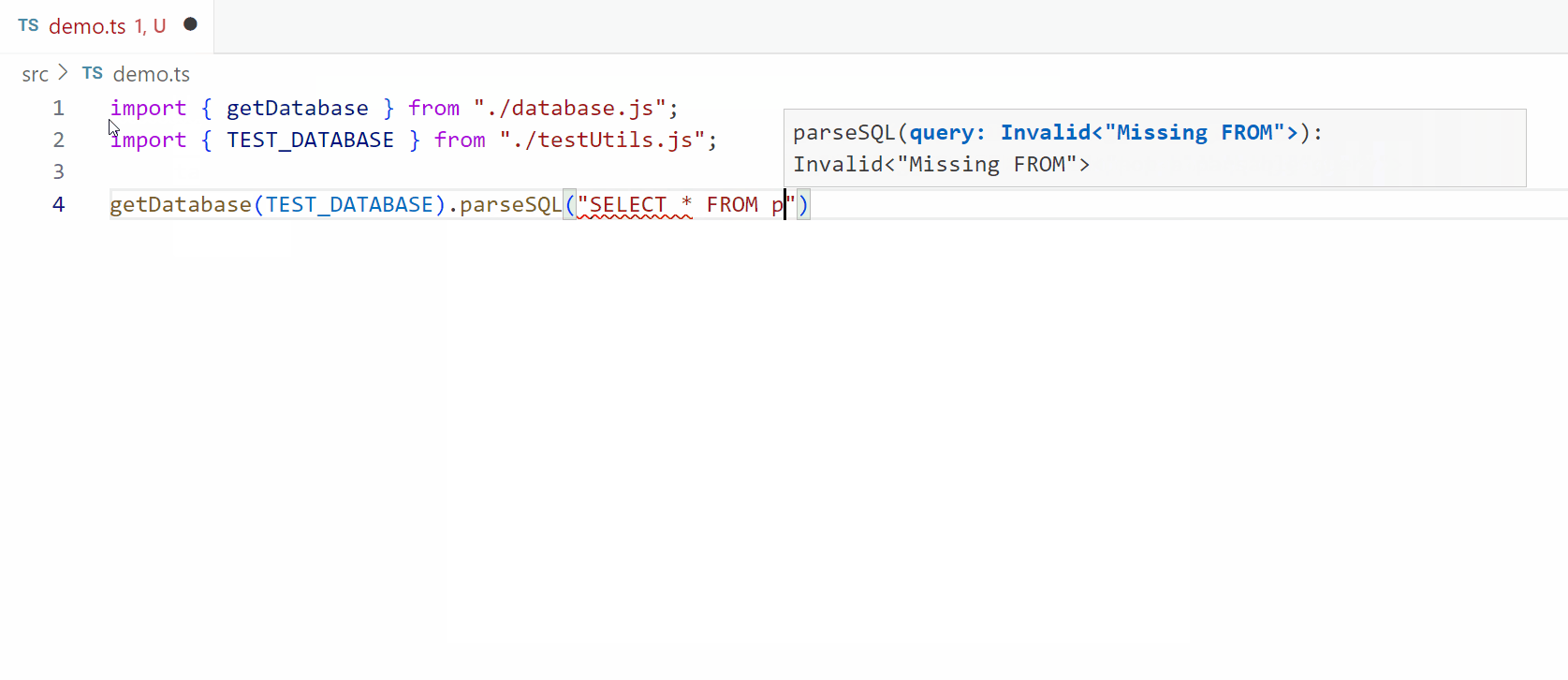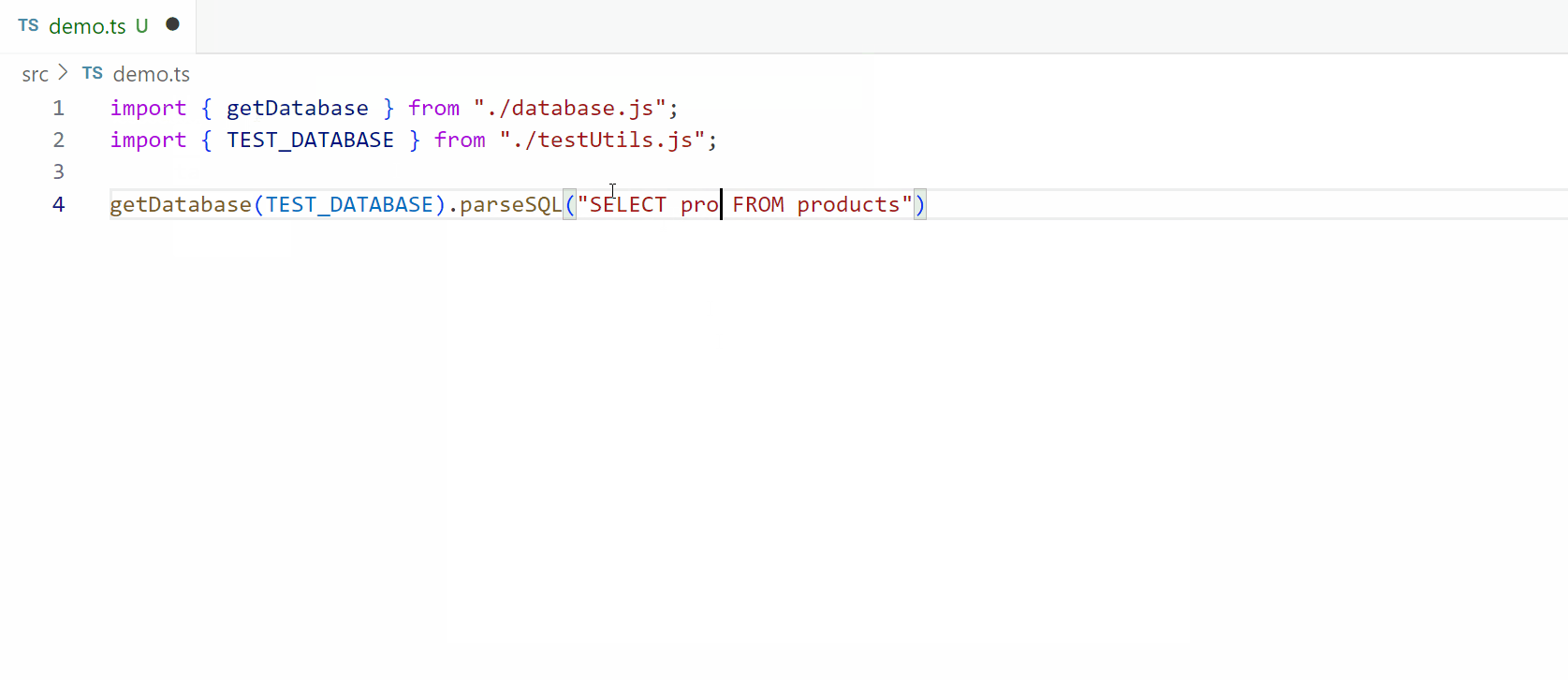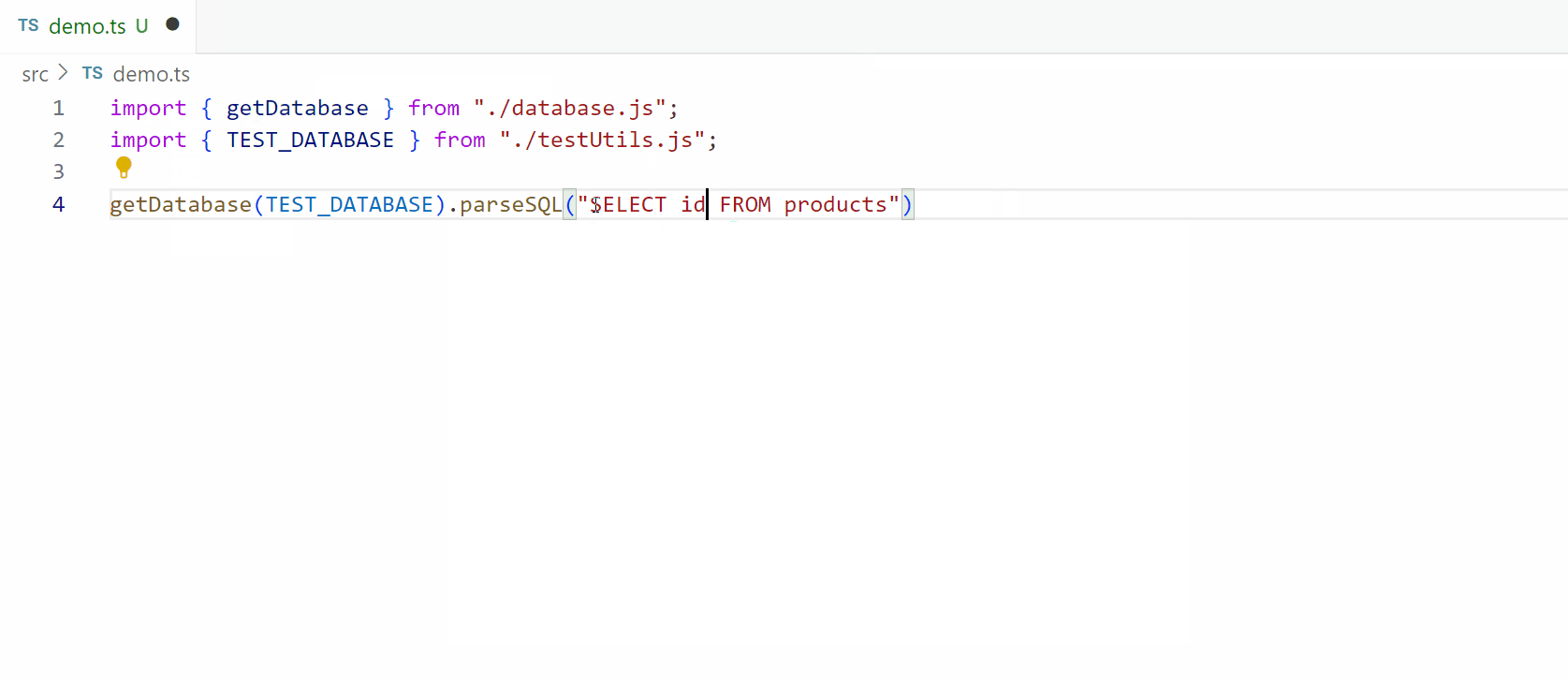
As before, all of the code you’ll see today is in our github repo under the medium/part-3 branch which I’ve linked below. You can also find branches for each of the other articles in the series so you can explore the progress on your own.
How We Transform strings -> SQL
This article is likely to be quite a bit longer than some of the others due to the nature of what we’re doing here: getting the compiler to treat a raw string as a fully formed type, while also parsing out the actual AST at the same time. Much like our AST or schema explorations, we won’t cover every single line of code or type, but there is a lot going on so I’m going to break this down in advance into a couple sections:
- Query Builders for manipulating the AST types and generating the actual tree nodes.
- Parsing a string into an AST using “normal” functions.
- Validating an AST against a schema to ensure the types are correct.
- Interpreting raw strings as a SQL AST and tying the other three sections together.
That ordering is mostly there to illustrate many of the concepts we are using at the compiler level to interpret strings as SQL, but if you want to just jump into the deep end of the pool feel free to skip ahead!
One other useful piece of information is that we are limiting the types of operations we support for this first pass through the world of parsing. Given that the scope of our full AST is quite large, we should break it down into some manageable pieces. In this article, the goal is to allow a simple select statement with columns and aliasing from a single table. In future articles, we’ll continue to expand the AST and work on extensions for other “non-standard” syntax options we want to support.
1. Query Builders
While parsing strings is obviously really cool, there are going to be times when we want to create some complicated queries that might be harder to write in raw SQL syntax. We also might not know how to write fully compliant queries for our engines and want to just create the AST and let someone else figure it out for us. In those cases, we’d like to have something that is similar to our schema builder from the last article to help us create the queries. Luckily, the process is very similar, but we’ll need some different utility types to validate the inputs. We’ll also need to be aware of future complexity since this will go a lot further than just table, column and key builders when we extend it later.
import type { SQLDatabaseSchema } from "../../schema/database.js"
import { createContext, type QueryContext } from "../context.js"
import { createFromQueryBuilder, type FromQueryBuilder } from "./from.js"
/**
* A builder that guides users through the types of queries we support.
*/
export interface QueryBuilder<Context extends QueryContext> {
/** Creates a {@link FromQueryBuilder} to start a select query */
select: FromQueryBuilder<Context>
}
/**
* Utility function to create a default {@link QueryBuilder}
*
* @param database The database to create the query against
* @returns A {@link QueryBuilder} for the database with an empty {@link QueryContext}
*/
export function createQueryBuilder<Database extends SQLDatabaseSchema>(
database: Database
): QueryBuilder<QueryContext<Database>> {
return new DefaultQueryBuilder(createContext(database).context)
}
/**
* Default implementation of our query builder
*/
class DefaultQueryBuilder<Context extends QueryContext>
implements QueryBuilder<Context>
{
private _context: Context
constructor(context: Context) {
this._context = context
}
get select(): FromQueryBuilder<Context> {
return createFromQueryBuilder(this._context)
}
}For now, this interface is pretty simple since we only support selects and that keeps down on the options we’ll need later. There are two main things to note with this implementation:
- We are providing a property
selectto guide the user to start a select statement. I find this to be a nice bit of syntactic sugar since intellisense can help guide query creation for others who may not fully know the underlying SQL syntax. - There is a
QueryContextthat we are including in the type definition which needs some further explanation
Query Context
If we think about all of the different things that we could do within a single query, the complexity of the problem quickly explodes. Some of that was apparent in the recursive and circular type definitions that came up for our AST, but there is actually another problem when we consider the database schema itself. The reason for the recursion is that queries can define temporary named “tables” that only exist during the scope of that specific query. It’s actually worse than that as well because not all of the named tables are accessible by all of the other parts of the query. 😬
To deal with these cases, we’re going to introduce a new type called a QueryContext that helps us track all of this information as the query is built.
/**
* The current context for a given query
*/
export type QueryContext<
Database extends SQLDatabaseSchema = SQLDatabaseSchema,
Active extends SQLDatabaseTables = IgnoreEmpty,
Returning extends SQLColumnSchema | number = SQLColumnSchema | number
> = {
database: Database
active: Active
returning: Returning
}As we can see, this object isn’t too complicated and leverages the existing types that we already created for the schema. A quick overview of this type would be:
Database: This is the current schema that the query has access to when looking for tables to get data from. It will match the database schema at the beginning but may be changed by other operations.Active: This is the schema that is currently being used by the query and is modified heavily depending on what is processed. The difference betweenDatabaseandActiveis that many components of a query cannot access the rawDatabaseschema itself but must work instead of the current active scope they have access to. We copy items from theDatabaseinto theActiveschema when they are referenced in a FROM clause (or JOIN clause later) and can also insert them with an alias so we ensure the query usestinstead oftablewhen we do something likeFROM table AS t.Returning: This isn’t going to be used much just yet, but it represents the shape of the rows returned by the query. In general, most databases will default an UPDATE, INSERT or DELETE to simple return a count of records modified while a SELECT returns the columns as defined. This explains the type ofSQLColumnSchema | numberthat we use to represent valid values.
Query Context Builders
Since our pattern for handling objects is to use builders everywhere else, we’ll also support them for the QueryContext objects.
/**
* Create a new builder for the given database
*
* @param database The database to use
* @returns A new {@link QueryContextBuilder}
*/
export function createContext<Database extends SQLDatabaseSchema>(
database: Database
): QueryContextBuilder<Database> {
return new QueryContextBuilder<Database>(<
QueryContext<Database, IgnoreEmpty, number>
>{
database,
active: {},
returning: 0, // This could be any number, we don't care
})
}
/**
* Create a builder using the existing context
*
* @param context The {@link QueryContext} to use
* @returns A new {@link QueryContextBuilder}
*/
export function modifyContext<Context extends QueryContext>(
context: Context
): QueryContextBuilder<Context["database"], Context> {
return new QueryContextBuilder<Context["database"], Context>(context)
}
/**
* Class used for manipulating {@link QueryContext} objects
*/
class QueryContextBuilder<
Database extends SQLDatabaseSchema,
Context extends QueryContext<Database> = QueryContext<Database>
> {
private _context: Context
constructor(context: Context) {
this._context = context
}
/**
* Retrieve the current Context
*/
get context(): Context {
return this._context
}
/**
* Add a table with the given definition to the context
*
* @param table The table to add
* @param builder The function to use for building the table or schema
* @returns An updated context builder
*/
add<Table extends string, Updated extends SQLColumnSchema>(
table: CheckDuplicateKey<Table, Context["active"]>,
builder: ColumnSchemaBuilderFn<IgnoreEmpty, Updated> | Updated
): QueryContextBuilder<
Database,
ActivateTableContext<Context, ParseTableReference<Table>, Updated>
> {
// Modify the schema
const schema =
typeof builder === "function"
? builder(createColumnSchemaBuilder()).columns
: builder
// Add the table
Object.defineProperty(this._context["active"], table as string, {
enumerable: true,
writable: false,
value: { columns: schema },
})
// Ignore the typing we know it is correct here
return this as unknown as QueryContextBuilder<
Database,
ActivateTableContext<Context, ParseTableReference<Table>, Updated>
>
}
/**
* Copy the schema from the database into the active set
*
* @param table The table to copy the definition from
* @returns An updated context builder
*
* @template Table The table from the database to copy
*/
copy<Table extends TableReference>(
table: CheckDuplicateTableReference<Table, Context["active"]>
): QueryContextBuilder<
Database,
ActivateTableContext<
Context,
Table,
GetTableSchema<Context, Table["table"]>
>
> {
const t = table as unknown as Table
return this.add(
t.alias as CheckDuplicateKey<string, Context["active"]>,
this.getTableSchema(t.table)
)
}
/**
* Retrieve the {@link SQLColumnSchema} from the database or active context
* for the given table name
*
* @param table The table to find
* @returns The {@link SQLColumnSchema} for the table
*/
private getTableSchema(table: string): SQLColumnSchema {
if (table in this._context["database"]["tables"]) {
return clone(this._context["database"]["tables"][table]["columns"])
} else if (table in this._context["active"]) {
return clone(
(
(this._context["active"] as IgnoreAny)[
table
] as unknown as SQLTableSchema
)["columns"]
)
}
throw new Error("Failed to locate table in active or database schemas")
}
/**
* Update the return type of the context
*
* @param schema The schema for the return type
* @returns An updated context
*
* @template Schema The new return schema
*/
returning<Schema extends SQLColumnSchema>(
schema: Schema
): QueryContextBuilder<
Database,
ChangeContextReturn<Database, Context, Schema>
> {
Object.defineProperty(this._context, "returning", {
enumerable: true,
writable: false,
value: schema,
})
return this as unknown as QueryContextBuilder<
Database,
ChangeContextReturn<Database, Context, Schema>
>
}
}We allow access to the builder through the two utility functions createContext and modifyContext which take either a database or an existing context to continue modifications. Just like our schema builders, we are manipulating the objects directly via the Object.defineProperty method to create new fields. Note that we need to use a utility clone method when copying tables because they can be changed between aliased versions of the same table and normally we’re only passing references around. We also need a getTableSchema method to find the table since it could exist in either the original Database OR the current Active schema.
There are a few utility types that are associated with the builder that are utilized to ensure type safety. Most of them are doing the equivalent of what the functional code does, just with the type system. As a concrete example, take a look at the GetTableSchema type compared to the private builder method:
/**
* Retrieve the {@link SQLColumnSchema} from the database or active context
* for the given table name
*
* @param table The table to find
* @returns The {@link SQLColumnSchema} for the table
*/
private getTableSchema(table: string): SQLColumnSchema {
if (table in this._context["database"]["tables"]) {
return clone(this._context["database"]["tables"][table]["columns"])
} else if (table in this._context["active"]) {
return clone(
(
(this._context["active"] as IgnoreAny)[
table
] as unknown as SQLTableSchema
)["columns"]
)
}
throw new Error("Failed to locate table in active or database schemas")
}
/**
* Retrieve the schema for the given table from the database or active portions
* of the context
*/
type GetTableSchema<
Context extends QueryContext,
Table extends string
> = Context extends QueryContext<infer Database, infer Active, infer _>
? [Table] extends [StringKeys<Database["tables"]>]
? Database["tables"][Table]["columns"]
: [Table] extends [StringKeys<Active>]
? Active[Table]["columns"]
: never
: neverThis is a really important concept that you’ll want to focus on when we get to the parsers. For the most part, what we see in the functional parsing of a string with code is nearly identical to what we are having the TypeScript compiler do for us. The syntax is different and we’re forced to do some strange things to make everything work at scale, but you’ll see when we get to the parsing that everything our functions are doing, the type system can *mostly* replicate.
Back To Query Builders
Now that we have a solid understanding of the QueryContext and it’s role in the builders, we can start exploring the classes themselves. The next available builder we see is the FromQueryBuilder which is an intermediate stage in our builders.
/**
* Start selection from a table in the context
*/
export interface FromQueryBuilder<Context extends QueryContext> {
/**
* Choose a table to select data from and optionally alias it
*
* @param table The table or table alias to select from
*/
from<Table extends AllowAliasing<GetContextTables<Context>>>(
table: Table,
): SelectedColumnsBuilder<
ActivateTableContext<Context, ParseTableReference<Table>>,
ParseTableReference<Table>
>
}This interface is only a few lines but does have one of the interesting features we’re leveraging in the AllowAliasing type. One of the things that we can do in our statement is to select a table Table with an alias Table AS t which could be anything that is a valid string. We can now start leveraging another TypeScript feature to allow us to infer the shape of a string.
/**
* Utility type to allow aliasing of the value
*/
export type AllowAliasing<Value extends string> = Value | AliasedValue<Value>
/**
* A value that can have an alias
*/
export type AliasedValue<Value extends string> = `${Value} AS ${string}`These two lines represent the other reason I really wanted to try to make a SQL parser in TypeScript and are key to enabling most of the string manipulations we’ll see later. The first type is pretty simple in that it says we can allow anything that is Value or an aliased version of that type. The second type has some string templating syntax you’ve likely come across before. Using it in a type definition has a pretty big change though. It says that the type represented by AliasedValue is satisfiable by ANY string that starts with ${Value} AS . The ${string} portion is what tells the compiler anything that can be a string is valid here.
Template Literal Types
The above is an example of a template literal type in TypeScript. These are types that define the shape of valid strings that satisfy the type and can use string literals to achieve that. This means that you can create restricted strings (not regex…yet) based on some other combined values and treat them as types. 😮
Alright, this is awesome information for our parser, we’ll just use string template literals and we’re done…right?…right??!
There are some serious and significant problems with template literals that we need to cover that make them amazingly powerful, but also really problematic. The first thing to note about them is that they are essentially union types that are created by the compiler behind the scenes for you as a courtesy. What gets ugly about this very quickly is that your usage of them can exceed the max valid union size which ends the party.
As a scary example, remember that we are creating an aliased type like this:
/**
* Utility type to allow aliasing of the value
*/
export type AllowAliasing<Value extends string> = Value | AliasedValue<Value>The easy assumption about this is that Value is a single string, but that is NOT the case. We’re using it in combination with:
from<Table extends AllowAliasing<GetContextTables<Context>>>Value in this case is the union of all the tables that are available in the context, which might get rather large depending on the shape of our database. In our case, it’s lucky that we’re only doing a template literal with ${string} as the combination, as it keeps our cardinality (the number of total combinations) limited to the number of keys in our Context[‘Database']['tables’] object. However, if we were to say, join that with the set of column names to try to get all Table.Column possibilities, that would cause our compiler to give up as the number of combinations there is just massive.
SelectedColumnsBuilder
Case in point, we’re going to run into that issue in the very next type we look at in the SelectedColumnsBuilder :
/**
* Interface that can provide the columns for a select builder
*/
export interface SelectedColumnsBuilder<
Context extends QueryContext = QueryContext,
Table extends TableReference = TableReference
> extends QueryAST<SelectClause<"*", Table>> {
/**
* Choose the columns that we want to include in the select
*
* @param columns The set of columns to select
*/
columns<
Columns extends AllowAliasing<GetSelectableColumns<Context>>[]
>(
...columns: AtLeastOne<Columns>
): SelectBuilder<Context, VerifyColumns<Columns>, Table>
}Given that we need to choose valid columns that may also have similar names as other columns in different tables, we need to be able to identify what specific column we are accessing. The id column in one table might be a bigint while another might be a string. Getting around this is done with some utility types and we’ll try to keep in mind the problems with template literal types when looking at the design for them.
/**
* Retrieve the names of all of the selectable columns
*/
export type GetSelectableColumns<Context extends QueryContext> =
Context extends QueryContext<infer _DB, infer Active, infer _Ret>
? GetColumnNames<Active>
: never
/**
* Retrieve the set of column names we support in our select queries
*/
type GetColumnNames<Schema extends SQLDatabaseTables> = {
[Table in StringKeys<Schema>]: {
[Column in StringKeys<Schema[Table]["columns"]>]: [Column] extends [
GetUniqueColumns<Schema>
]
? Column
: `${Table}.${Column}`
}[StringKeys<Schema[Table]["columns"]>]
}[StringKeys<Schema>]
/**
* Get all of the columns that are active but NOT part of the current table
*/
type GetOtherColumns<
Schema extends SQLDatabaseTables,
Table extends keyof Schema
> = {
[Key in keyof Schema]: Key extends Table
? never
: StringKeys<Schema[Table]["columns"]>
}[keyof Schema]
/**
* Get the set of Unique columns across all active tables
*/
type GetUniqueColumns<Schema extends SQLDatabaseTables> = {
[Key in keyof Schema]: UniqueKeys<
StringKeys<Schema[Key]["columns"]>,
GetOtherColumns<Schema, Key>
>
}[keyof Schema]
/**
* Get the set of unique keys between the two sets
*/
type UniqueKeys<Left extends string, Right extends string> = {
[V in Left]: [V] extends [Right] ? never : V
}[Left]First off, we don’t want to get columns from every table in the database, we only need to retrieve columns from those tables that are part of this select. This is why our QueryContext has that Active set of tables to help reduce the scope of what we can do and prevent union type explosion. That’s not necessarily enough though as we will have multiple active tables later when we join things. If we just did a naive ${Table}.${Column} template literal for everything that might also stop compilation while generating completely invalid table/column pairs. To prevent that, we iterate through all of the keys in each table and join them only to their table, limiting the set of union strings we generate.
There is one other utility that we put in place where we look for “unique” columns. While many column names are common in schemas, there are also quite a few that are unique to a specific table. If we always force the user to enter the table and then the column, it’s a bunch of extra typing and feels very un-SQL (it doesn’t have that problem). We only need to include the table when there is a collision between column names to make sure we don’t accidently return the wrong value.
We talked about type inference earlier and trying to limit what the compiler has to know at any given time, which is why we split these types up into a couple of different components. GetOtherColumns gets all the columns from the other tables in our schema. GetUniqueColumns gets the unique columns from a given table by comparing each to the results of GetOtherColumns while the final UniqueKeys type just does a check for the keys that are not an intersection with the other tables. By dividing this work up, we allow the compiler to try to cache as much data as possible and hopefully not evaluate too many options at any given time.
Using all of that information, we can envision what is going on in the builder demonstration below and how it’s inferring all of that data for us:
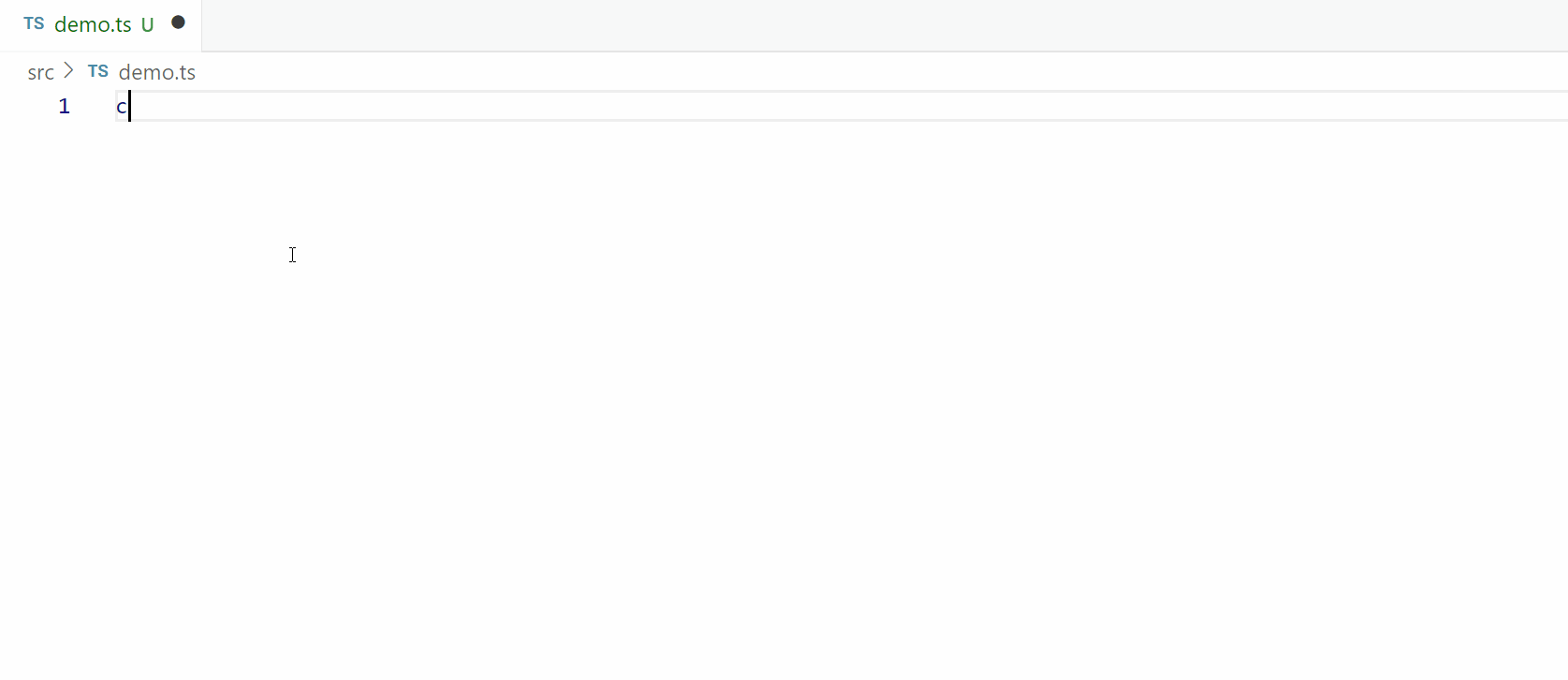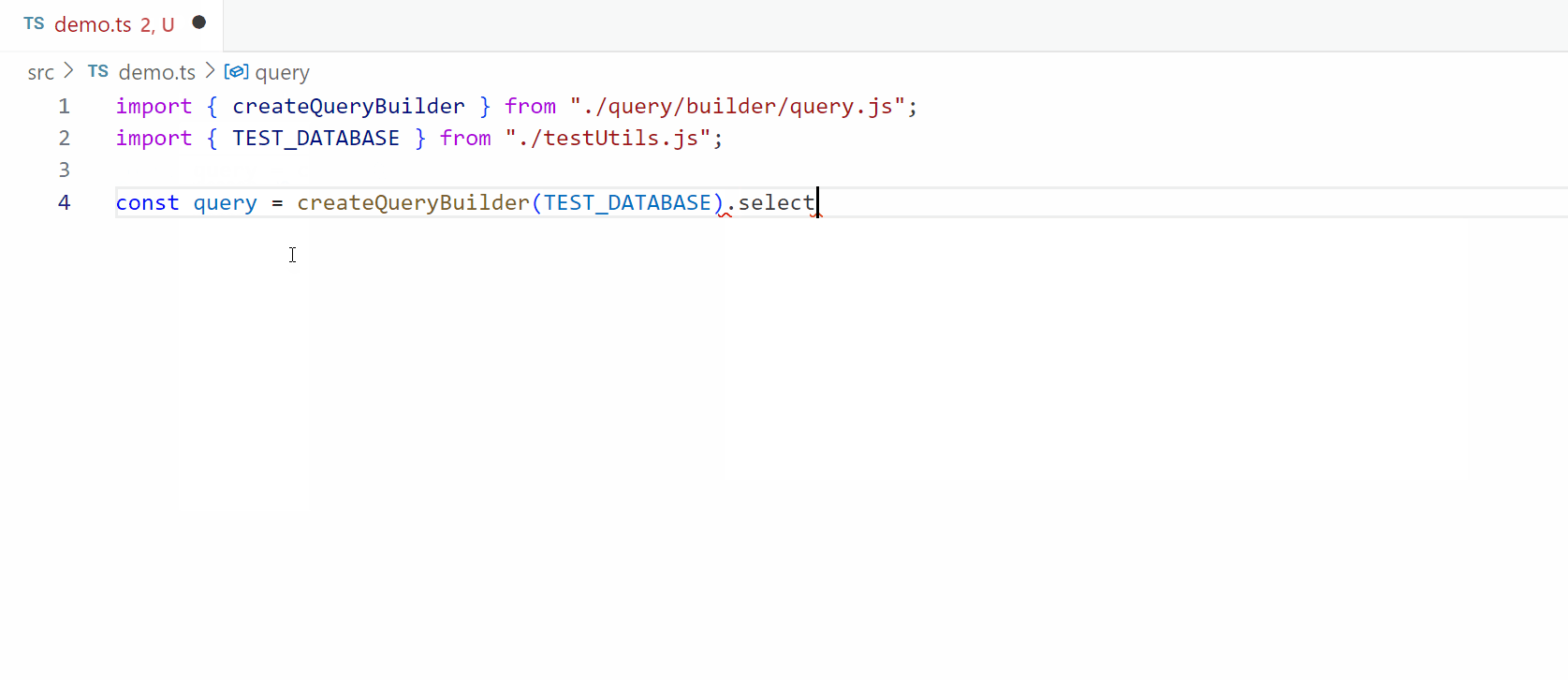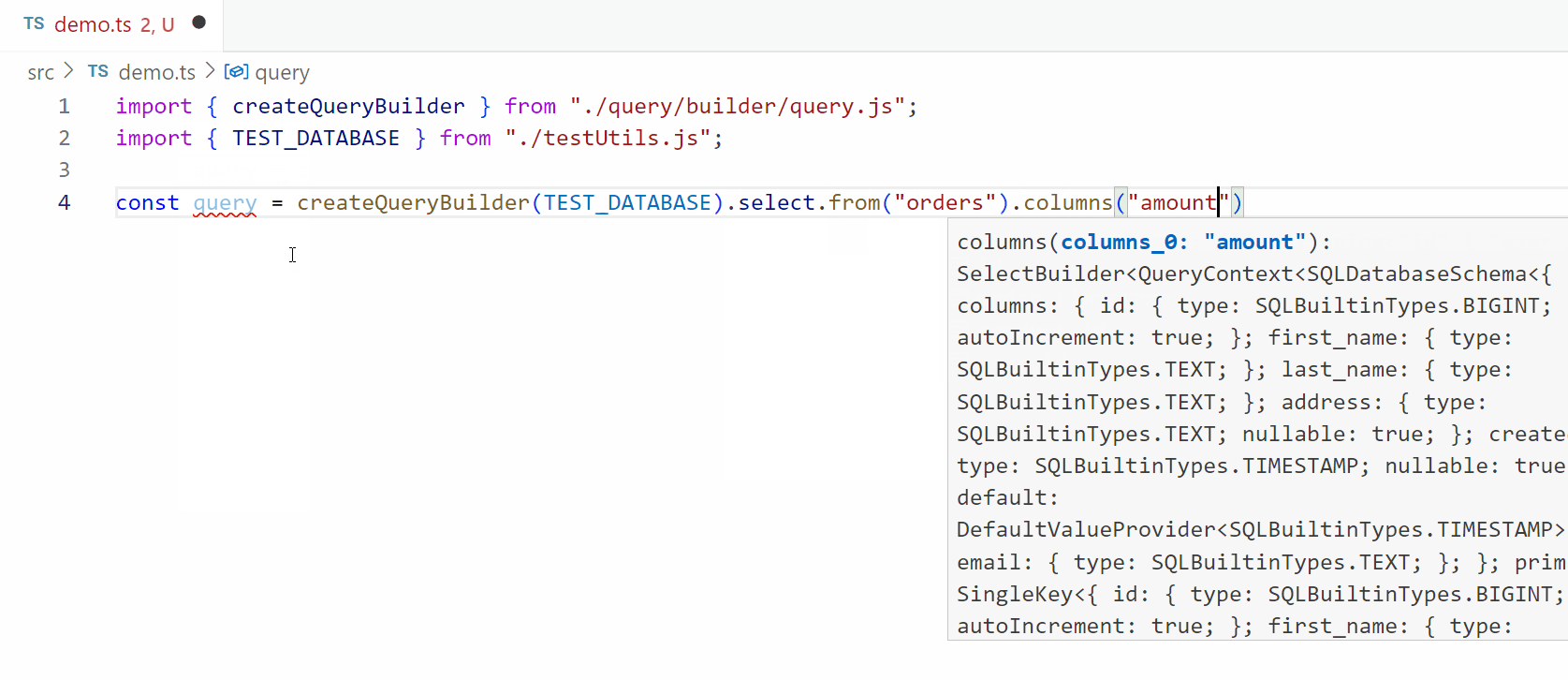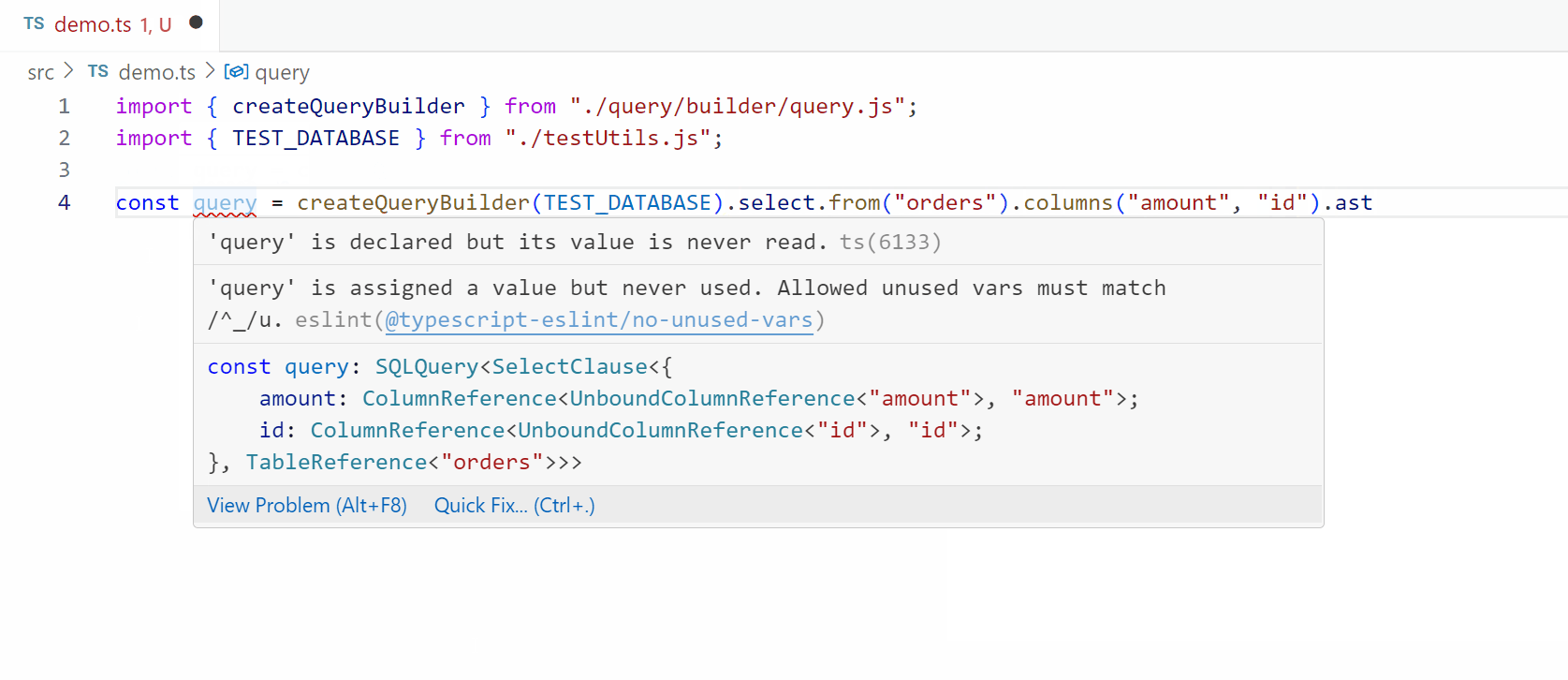
2. Parsing SQL the “normal” way
Now that we have our builders, we can take a look at how we could use them to parse a SQL query from a string using normal programming techniques. Since a lot of the complex type interactions were done in the previous section, this should be a little faster to walk through. Note that we’ll be touching on some concepts that are important for the final TypeScript approach we take at the end so skimming at least is recommended.
/**
* Class to help with Query parsing
*/
export class QueryParser<Database extends SQLDatabaseSchema> {
private _database: Database
constructor(database: Database) {
this._database = database
}
/**
* Retrieve the query builder at this point in time
*/
get builder(): QueryBuilder<QueryContext<Database>> {
return createQueryBuilder(this._database)
}
/**
* Parse the given query into an AST
*
* @param query The query to parse
* @returns A fully parsed SQL query
*/
parse<T extends string>(query: T): ParseSQL<T> {
return parseQueryClause(normalize(query)) as ParseSQL<T>
}
}
/**
* Parse the query clause
*
* NOTE: This does NOT check anything for validity as that should be done via
* the type system. If called outside of this context things WILL break
*
* @param s the string to parse
* @returns A generic SQLQuery
*/
function parseQueryClause(s: string): SQLQuery {
const tokens = s.split(" ")
switch (tokens.shift()!) {
case "SELECT":
return {
type: "SQLQuery",
query: parseSelectClause(tokens),
}
default:
throw new Error(`Cannot parse ${s}`)
}
}That doesn’t look too bad! It’s short because we only support a limited syntax so far and there really should only be two main things that stand out:
- We are parsing a SelectClause from a string that has been split into segments which seems…strange.
- We are calling a function called
normalizeon the string that we’re given as an input toparse.
There are also some additional types related to the string parsing that you can see, specifically ParseSQL<T> but I promise we’ll get there soon. 😉 Before we jump in the the parseSelectClause method, we should first take a peek at this normalize function to see what it’s doing.
/**
* This function is responsible for making sure that the query string being
* processed has a very specific shape. The rules for that are as follows:
*
* 1. All whitespace should be removed and replaced with a single space
* 2. We want to split based on commas or open/close parenthesis but keep those characters
* 3. We ensure that each remaining "word" is normalized
* 4. We combine it all back together as a single collapsed string
*
* @param query The query string to normalize
* @returns A {@link NormalizeQuery} string
*/
export function normalizeQuery<T extends string>(query: T): NormalizeQuery<T> {
return query
.split(/\s|(?=[,()])|(?<=[,()])/g)
.filter((s) => s.length > 0)
.map((s) => normalizeWord(s.trim()))
.join(" ") as NormalizeQuery<T>
}
/**
* Ensure that keywords are uppercase so we can process them correctly
*
* @param word The word to check against our normalization keys
* @returns A normalized version of the word
*/
export function normalizeWord(word: string): string {
return NORMALIZE_TARGETS.indexOf(word.toUpperCase()) < 0
? word
: word.toUpperCase()
}To start off, there are a LOT of ways that we could tokenize and process the strings to extract the SQL, especially since we have regex at our disposal. However, to help understand the final solution, I’ve worked to keep these more closely aligned with what the type system is doing to help explain everything. Eventually we can replace all of this with something a bit more efficient.
That being said, let’s quickly look at what we’re doing. We are splitting the string into segments based on a few key structural characters, removing all unnecessary whitespace and then ensuring that words that are “normalized” are uppercase. The normalized words are ones that have contextual meaning when processing and we want to ensure we find them:
/**
* The set of logical keys that affect grouping in filters
*/
export const LOGICAL_KEYS = ["AND", "OR", "NOT"]
/**
* The set of keys that hint at the type of query being processed
*/
export const QUERY_KEYS = ["SELECT", "UPDATE", "INSERT", "DELETE", "WITH"]
/**
* The set of keys that indicate the end of the where clause
*/
export const WHERE_KEYS = ["HAVING", "GROUP", "OFFSET", "LIMIT", "ORDER"]
/**
* The set of keys that indicate the end of a join clause
*/
export const JOIN_KEYS = [
"JOIN",
"OUTER",
"INNER",
"FULL",
"LEFT",
"RIGHT",
"LATERAL",
]
/**
* The set of keys that indicate the from clause has ended
*/
export const FROM_KEYS = ["WHERE", ...WHERE_KEYS, ...JOIN_KEYS]
/**
* The full set of all keys
*/
export const NORMALIZE_TARGETS = [
...QUERY_KEYS,
...FROM_KEYS,
...LOGICAL_KEYS,
"FROM",
"AS",
"UNION",
"EXTRACT",
"MINUS",
"INTERSECT",
"ON",
"SET",
]We have to make sure that we uppercase them in our type because the database doesn’t actually care about case sensitivity in most cases, but for our type inference to work later on, it most definitely matters. T extends "as” will NOT match AS , As , or aS but the database handles those all just fine. To cut down on the number of things we have to check, we could either do uppercase or lowercase and I happened to choose uppercase. If we changed that to be lowercase, it doesn’t change the logic much but this makes it easier to see when debugging the types as SELECT stands out easier to my eyes than select.
So, at this point we have a string that is formatted with useful markers either capitalized or split out by single spaces. That helps explain why we do a query.split(' ') in the lower level query parsing method and then check to see if the first token is SELECT. Now let’s take a look at what we’re doing with the rest of those string tokens in the select parser.
/**
* Parse out the given select clause
*
* @param tokens The tokens to parse
* @returns A {@link SelectClause}
*/
export function parseSelectClause(tokens: string[]): SelectClause {
return {
type: "SelectClause",
...parseSelectedColumns(takeUntil(tokens, ["FROM"])),
...parseFrom(takeUntil(tokens, FROM_KEYS)),
}
}That’s extremely short and mostly relies on a few other helpers, which makes some sense since a select is just a collection of other information. We can see another of our utility methods there, takeUntil which looks like this:
/**
* Extract the next tokens until a terminal character is hit or all tokens are processed
*
* @param tokens The tokens to process
* @param terminal The words that terminate the process
* @returns The next set of tokens between the start and the terminal character
*/
export function takeUntil(tokens: string[], terminal: string[]): string[] {
const ret = []
let cnt = 0
// Don't count tokens that are encountered as part of a subquery between () pairs
while (tokens.length > 0 && terminal.indexOf(tokens[0]) < 0 && cnt === 0) {
const token = tokens.shift()!
ret.push(token)
if (token === "(") {
cnt++
} else if (token === ")") {
cnt--
}
}
return ret
}This is pretty simple outside of one part that needs a bit more explanation. We simply process through the tokens until we hit one of the terminal keywords at which point we stop and return back whatever we’ve gotten so far. We do change the original tokens since we’re shifting values off of the original so there is a bit of a hidden side effect there.
The big thing to take away from this where we are saying that a terminal token is “valid”. This doesn’t affect our first parser at all, but will become a huge pain when we start processing subqueries because the WHERE keyword we are looking for might not be related to this segment and may be part of a subquery instead. 😱 To get around this, we can simply count the number of open parenthesis we have seen and decrement when we come across a closed parenthesis. If the current count is 0, it *should* be on the same level as whatever we are processing and skipped over any subquery specification that is present.
The main note you should take away from this is that we said we are “counting” the number of times that we saw something. Later on we’re going to be using ONLY types to accomplish this, which means there is something fun that we’ll have to handle. We’ll take one last peek at the code that parses the columns:
/**
* Parse the selected columns
*
* @param tokens The tokens that represent the select clause
* @returns A {@link SelectColumns} or '*' depending on the input
*/
export function parseSelectedColumns(tokens: string[]): {
columns: SelectColumns | "*"
} {
// Join everything up and split out the commas
const columns = tokens.join(" ").split(" , ")
// If only one column and it's '*' just return that
if (columns.length === 1 && columns[0] === "*") {
return {
columns: "*",
}
}
// Parse out the column references and add them to an empty object
return {
columns: columns
.map((c) => parseColumnReference(c))
.reduce((v, r) => {
Object.defineProperty(v, r.alias, { enumerable: true, value: r })
return v
}, {}),
}
}As with most of the other parsing, it’s pretty straight forward and looks pretty similar to what you might expect. We simply join all the tokens together with the space we removed, then split out the column specifiers which will always be {space},{space} due to our normalization. Then we can just take a look at the syntax to figure out if it’s an aliased string X AS Y and if it has a table T.X AS Y to determine the AST shape. Then we just reduce them all into an object and we’re done!
3. AST Validations
At this point, we now have the ability to create a query AST via our builders or parse one through our functions. The last step before we can put it all together is to start working on validation against our database. Just because we have a valid statement like SELECT * FROM foo doesn’t mean that it will run, especially if we don’t have a table called foo! We can optionally allow our functional code to look at the database structure and compare that to the AST, but we want the feedback to come at compile time so we should stick to type only validations for this portion.
We will be heavily relying on our Invalid type to provide feedback as you’ll see right away in the main query validation entry point:
/**
* Type to verify a query is valid to parse
*/
export type CheckQuery<
Database extends SQLDatabaseSchema,
T extends string
> = ParseSQL<T> extends SQLQuery<infer Query>
? CheckInvalid<VerifyQuery<Database, SQLQuery<Query>>, T>
: ParseQuery<T> extends QueryClause
? CheckInvalid<VerifyQuery<Database, SQLQuery<ParseQuery<T>>>, T>
: Invalid<"Not a valid query string">
/**
* Utility type to see if the result is true or an invalid so we don't have to
* calculate types multiple times
*/
type CheckInvalid<T, R> = T extends true ? R : T
/**
* Entrypoint for verifying a query statement
*/
type VerifyQuery<
Database extends SQLDatabaseSchema,
Query extends SQLQuery
> = Query extends SQLQuery<infer Clause>
? Clause extends SelectClause<infer _Columns, infer _From>
? ValidateSelectClause<Database["tables"], Clause>
: Invalid<`Unsupported query type`>
: Invalid<`Corrupt or invalid SQL query`>So for the most part, we can see this is mainly done through a bunch of conditional types where we check to see if the type extends an expected value and then pass that value into a verifier. The expectation based on the CheckInvalid type is that the return type for a validation check is either going to be true or an Invalid that we’ll return back. This will cause the same TypeScript compilation errors we saw for invalid columns. With those expectations set, we can explore the select validation to see what is happening for an actual query.
/**
* Verify if the select clause is valid
*/
export type ValidateSelectClause<
Database extends SQLDatabaseTables,
Select extends SelectClause,
Active extends SQLDatabaseTables = IgnoreEmpty
> = Select extends SelectClause<infer Columns, infer From>
? From extends TableReference<infer Table, infer _>
? [Table] extends [StringKeys<Database>]
? ValidateSelectColumns<
AddTableToSchema<Table, Database[Table]["columns"], Active>,
Columns
>
: Invalid<`${Table} is not a table in the referenced schema`>
: Invalid<"Corrupt from clause">
: Invalid<"Invalid select clause">This is also pretty simple and just a bunch of conditional types. We ensure that the select clause is well formed with checks on the table being a reference (we don’t support subqueries yet…) and that the table is actually a named table in our database schema. If that passes, we then move on to checking the columns and simply return that result. This is actually where some of the only interesting things happen from a TypeScript perspective.
/**
* Ensure that the select columns are valid
*/
export type ValidateSelectColumns<
Active extends SQLDatabaseTables,
Columns extends SelectColumns | "*"
> = Columns extends "*"
? true
: Columns extends SelectColumns
? ValidateSelectedColumns<Active, ExtractSelectedColumns<Columns>>
: Invalid<"Invalid selected columns">
/**
* Extract the column references from the columns
*/
type ValidateSelectedColumns<
Active extends SQLDatabaseTables,
Columns
> = Columns extends [infer Column extends SelectedColumn, ...infer Rest]
? Rest extends never[]
? GetColumnReference<Column> extends ColumnReference<
infer Reference,
infer _Alias
>
? ColumnInActive<Active, Reference>
: Invalid<`Invalid or corrupt column reference`>
: GetColumnReference<Column> extends ColumnReference<
infer Reference,
infer _Alias
>
? ColumnInActive<Active, Reference> extends true
? ValidateSelectedColumns<Active, Rest>
: ColumnInActive<Active, Reference>
: Invalid<`Invalid or corrupt column reference`>
: Invalid<"Columns are not valid SelectedColumn[]">
/**
* Extract the column reference from the SelectColumn property
*/
type GetColumnReference<Selected extends SelectedColumn> =
Selected extends ColumnReference<infer Reference, infer _Alias>
? ColumnReference<Reference>
: Selected extends ColumnAggregate<
infer Reference,
infer _Agg,
infer _Alias
>
? Reference
: never
/**
* Verify that the column is part of the active set since don't want people
* pulling columns from tables that aren't part of the select clause
*/
type ColumnInActive<
Active extends SQLDatabaseTables,
Column extends UnboundColumnReference | TableColumnReference
> = Column extends TableColumnReference<infer Table, infer Col>
? [Col] extends [StringKeys<Active[Table]["columns"]>]
? true
: Invalid<`${Col} is not a column of ${Table}`>
: [Column["column"]] extends [
{
[Table in keyof Active]: StringKeys<Active[Table]["columns"]>
}[keyof Active]
]
? true
: Invalid<`${Column["column"]} is not a valid column`>
/**
* Extract the selected column properties as an array instead of a union
*
* NOTE: There is NO guarantee on the order these come back but that shouldn't
* matter for validation purposes...
*/
export type ExtractSelectedColumns<Columns extends SelectColumns> =
UnionToTuple<
{
[Key in StringKeys<Columns>]: Columns[Key]
}[StringKeys<Columns>]
>To make sense of what these types are doing, we can outline the general process:
- Verify if we have columns or a simple select
*. In case of the latter, there isn’t more to do. - We need to somehow transform the set of columns on the
SelectColumnstype into an array that we can check using our previously established loop pattern. - Verify that each column in the array exists on the active tables by checking for a table reference or unique column assumption where we just ensure that at least 1 table has that column. This is something we have a
TODOin the code to fix when we handle joins so we don’t end up with unknown column matching whereSELECT idmight refer to different column types on various tables and need to tell the user to be more specific. - If all of that checks out, return true.
A Necessary Bad Idea (for now…)
There is a pretty big gap in #2 above because turning a union into an array is…questionable at best. It can be done using the code below:
/**
* These type extensions shouldn't be used without serious thought to the fact
* they are hacks around unsupported functionality
*/
/**
* Utility type to convert a union to an intersection
*/
type UnionToIntersection<U> = (
U extends never ? never : (arg: U) => never
) extends (arg: infer I) => void
? I
: never
/**
* Utility type to convert a union to a tuple
*
* WARNING: This is unpredictable for ordering!
*/
export type UnionToTuple<T, A extends unknown[] = []> = UnionToIntersection<
T extends never ? never : (t: T) => T
> extends (_: never) => infer W
? UnionToTuple<Exclude<T, W>, [...A, W]>
: AAs you can see from the comments, there is a general consensus in the community that it’s probably a bad idea for a number of reasons.
However, without this we get stuck pretty fast when trying to validate or otherwise work with things because we can enforce some column type arrays in functions (see our primary/foreign keys as an example) but when we start trying to parse raw strings that just isn’t always an option.
Given that, let’s take a look at the biggest problem that comes out of the discussions in that thread, which is that order cannot be enforced. There is no way for us to ensure that A | B | C is always interpreted as [A, B, C]. However, this isn’t a huge issue for us right now because we don’t care about the order, just the fact that A, B & C all exist on the table. It also doesn’t matter as much for the select since anything in TypeScript turning a row set into an object ignores the key order when defining the properties.
const v1 = {
a: "foo",
b: "bar"
}
const v2 = {
b: "bar",
a: "foo"
}
// v1 === v2 (true)The above values are equivalent because they have the same type structure so we can get away with this for now. However, this is something we’re going to have to deal with when we get to things like ORDER BY clauses because in that case the order, like our keys, matters. There are a few things that I’ve been exploring that might work later, but for now we’re going to go ahead and leave this unsupported code in here, knowing that it has some issues, isn’t necessarily advised and we need to work on getting rid of it in the future (the next article or two).
Alright, with that out of the way, we can see that the rest of our code is happy because we can simply translate the keys into an array, then decorate that array of keys as the set of values in the type through our loop decoration and then validate each of the references is valid. Hurray, we can validate our select statements and see that in action in the gif at the top of this article!
4. Interpreting strings as SQL
We finally made it here and hopefully you at least skimmed some of the sections above. I’m going to try to outline things as well as I can here before we dive into code but to save everyone’s sanity I’m not going to go into great detail for how the concepts I explained above already work.
In the parsing section above, we outlined the process that we used for processing strings to build the AST in code which was roughly:
- Normalize the string to ensure we have a consistent representation of keywords and expected structural identifiers.
- Tokenize the string into individual components (as a string array)
- Read until we find one of our identifiers that indicates the end of the current section while ignoring anything between parenthesis (subqueries).
- Process the tokens between identifiers to identify the correct structural markers and repeat 2, 3, 4 as needed recursively.
So far in our articles, we have also learned how to do recursive calls in the type system to satisfy #4 above. We also saw that we can use template string types and as well as type inference to verify the structural components match our expectations allowing for #1 and #2. Finally, we saw in the second article how we can establish a looping pattern over an array of type objects with some modification or processing logic, allowing almost all of #3. However, we still have one outstanding problem:
- We need to be able to count the parenthesis we’ve seen so far so we can ignore subqueries.
Counting in the type system isn’t supported so we need a way to deal with that problem before we try to string the rest of the concepts together to write our parser.
Counting Without Numbers
The idea of counting in a normal way is completely out of the question since it’s not a language feature in the type system itself, but we can replicate it if we take advantage of the way a few other features work. Let’s take a look at the code for counting and explain what it’s doing:
/**
* Get the next value or undefined if >= 128
*/
export type Inc<T> = T extends keyof Increment ? Increment[T] : never
/**
* Get the previous value or undefined if <= 128
*/
export type Dec<T> = T extends keyof Decrement ? Decrement[T] : neverYup, only two single line types are required to increment and decrement, but we can also see two other types there that I haven’t pasted Increment and Decrement . The reason I didn’t paste them is that they are simply a hard coded array of numbers that are specifically shaped to make the types work and look like:
/**
* I'm not trying to support ANY number, if you're going more than 128 deep for
* some reason, you should probably be stopped lol
*/
type Increment = [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
//...As the comment suggests, each one of those type arrays has 128 numbers in them. The reason that this works is because of how arrays are defined in TypeScript. Each index in an array is actually a property that is accessed just like any other key except that they are numeric and not strings. So if you access myArr[0] you’re actually not accessing the first element in the array, but instead an element with the property key 0 . As for how our increment/decrement pattern works, we simply ask if T is a key of the array and if so, we grab the value at that property. Since Increment[0] is 1 we can now simulate counting, all within the type system. If we also combine this with a recursive type definition, we can start to envision how we can deal with parenthesis:
/**
* Keep aggregating the next token until the terminator is reached
*/
export type ExtractUntil<
T extends string,
K extends string,
N = 0,
S extends string = "",
> =
NextToken<T> extends [infer Token extends string, infer Rest extends string]
? Rest extends ""
? [Trim<S>]
: Token extends "("
? ExtractUntil<Rest, K, Inc<N>, `${S} (`>
: Token extends ")"
? ExtractUntil<Rest, K, Dec<N>, `${S} )`>
: [Token] extends [K]
? N extends 0
? [Trim<S>, Trim<`${Token} ${Rest}`>]
: ExtractUntil<Rest, K, N, `${S} ${Token}`>
: ExtractUntil<Rest, K, N, `${S} ${Token}`>
: neverWhat this type does is process the Next token in T and append it to the string S that we default to an empty string at the start. We also pass through the type N = 0 (this isn’t the number, it’s a specific type that can only have the value 0) and if the token that we see is an open parenthesis ( then we “increment” that number and if it’s a closing parenthesis ) we “decrement”. If our token extends whatever we are searching for in the type K then we can stop the process and return the string we collected so far as well as the remainder for future processing.
Putting It All Together
Alright, we have all the tools we said we need so it’s just a matter of putting them together in the correct order. There are a few other utilities we should take a look at before getting into our simple SELECT parser.
/**
* Custom split that is SQL aware and respects parenthesis depth
*/
export type SplitSQL<
T extends string,
Token extends string = ",",
S extends string = "",
> = T extends `${infer Left} ${Token} ${infer Right}`
? EqualParenthesis<`${S} ${Left}`> extends true
? [Trim<`${S} ${Left}`>, ...SplitSQL<Trim<Right>, Token>]
: SplitSQL<Right, Token, Trim<`${S} ${Left} ${Token}`>>
: EqualParenthesis<`${S} ${T}`> extends true
? [Trim<`${S} ${T}`>]
: Invalid<"Unequal parenthesis">
/**
* Test if ( matches ) counts
*/
type EqualParenthesis<T> = CountOpen<T> extends CountClosed<T> ? true : false
/**
* Count the ( characters
*/
type CountOpen<T, N extends number = 0> = T extends `${infer _}(${infer Right}`
? CountOpen<Right, Inc<N>>
: N
/**
* Count the ) characters
*/
type CountClosed<
T,
N extends number = 0,
> = T extends `${infer _})${infer Right}` ? CountClosed<Right, Inc<N>> : NThis is a slightly different utility that is responsible for splitting up a string into chunks that also has to be parenthesis aware. It leverages string template typing to find the next pattern that matches our target tokens and then uses the a type to count the number of open and closed parenthesis in a given chunk and if they have a matching type (not a number) then it *should* be safe to split on. There are some edge cases with invalid parenthesis groupings that would be false matches, but we can cut out a lot of logic by assuming that someone typing a query is generally not malicious. Since you have to provide the string at compile time we don’t have to worry about too many injection attacks, etc.
For normalizing the string, we can leverage some other manipulations to ensure the correct shape before doing any of our other checks:
/**
* Ensure a query has a known structure with keywords uppercase and consistent spacing
*/
export type NormalizeQuery<T> = SplitJoin<
SplitJoin<SplitJoin<SplitJoin<SplitJoin<T, "\t">, "\n">, ",">, "(">,
")"
>
/**
* Normalize the values by ensuring capitalization
*/
export type NormalizedJoin<T, Keywords = NormalizedKeyWords> = T extends [
infer Left,
...infer Rest
]
? Rest extends never[]
? Check<Left & string, Keywords>
: `${Check<Left & string, Keywords> & string} ${NormalizedJoin<
Rest,
Keywords
> &
string}`
: ""
/**
* Split and then rejoin a string
*/
type SplitJoin<T, C extends string = ","> = Join<SplitTrim<T, C>>
/**
* Split and trim all the values
*/
type SplitTrim<
T,
C extends string = ","
> = Trim<T> extends `${infer Left}${C}${infer Right}`
? [...SplitTrim<Left, C>, Trim<C>, ...SplitTrim<Right, C>]
: [NormalizedJoin<SplitWords<Trim<T>>>]
/**
* Check if a value is a normalized keyword
*/
type Check<T extends string, Keywords> = [Uppercase<Trim<T>>] extends [Keywords]
? Uppercase<Trim<T>>
: Trim<T>
/**
* Set of keywords we need to ensure casing for
*/
type NormalizedKeyWords =
| "SELECT"
| "INSERT"
| "UPDATE"
| "DELETE"
//...several more after thisSince we can’t use a regex, we have to just manually provide the characters we want to split out (either to remove for whitespace or use for identifiers like (, ), or ','). These types will allow us to split out the strings recursively, checking if they match one of our known keywords and then rebuild with spaces to ensure that our query has a standard shape.
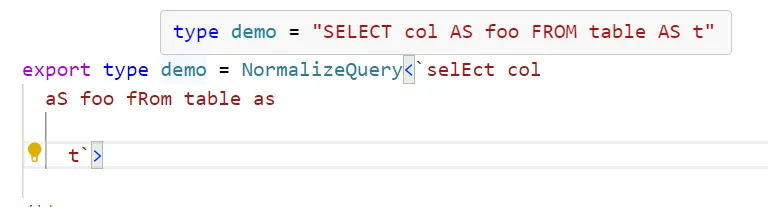
Now that we have a query with a mostly predictable shape, we can go ahead and parse it using some specific utility types.
/**
* Type to parse a SQL string into an AST
*/
export type ParseSQL<T extends string> = CheckSQL<ParseQuery<T>>
/**
* Type to parse a query segment
*/
export type ParseQuery<T extends string> = ParseSelect<NormalizeQuery<T>>
/**
* Validate the query structure or pass through the likely Invalid
*/
type CheckSQL<Query> = [Query] extends [never]
? Invalid<"not a parsable query">
: Query extends QueryClause
? SQLQuery<Query>
: QueryThis is the elusive ParseSQL type from the sections above and hopefully it makes a lot more sense what is going on as we look at the rest of the SQL specific types. Since we only support SELECT, we just try to parse all queries with ParseSelect after normalizing the type and then use the CheckSQL type to look for invalid types.
/**
* Parse the next select statement from the string
*/
export type ParseSelect<T extends string> =
NextToken<T> extends ["SELECT", infer Right extends string]
? CheckSelect<ExtractColumns<Right>>
: never
/**
* Check to get the type information
*/
type CheckSelect<T> =
Flatten<T> extends Partial<SelectClause<infer Columns, infer From>>
? Flatten<SelectClause<Columns, From>>
: T
/**
* Parse out the columns and then process any from information
*/
type ExtractColumns<T extends string> =
ExtractUntil<T, "FROM"> extends [
infer Columns extends string,
infer From extends string,
]
? CheckColumns<Columns> extends true
? StartsWith<From, "FROM"> extends true
? Columns extends "*"
? {
columns: Columns
} & ExtractFrom<From>
: {
columns: ParseColumns<SplitSQL<Columns>>
} & ExtractFrom<From>
: Invalid<"Failed to parse columns">
: CheckColumns<Columns>
: Invalid<"Missing FROM">
/**
* Parse the columns that were extracted
*/
type ParseColumns<T, O = object> = T extends [
infer Column extends string,
...infer Rest,
]
? Rest extends never[]
? ParseColumnReference<Column> extends ColumnReference<infer C, infer A>
? Flatten<
O & {
[key in A]: ColumnReference<C, A>
}
>
: Invalid<`Invalid column reference`>
: ParseColumnReference<Column> extends ColumnReference<infer C, infer A>
? Flatten<
ParseColumns<
Rest,
Flatten<
O & {
[key in A]: ColumnReference<C, A>
}
>
>
>
: Invalid<`Invalid column reference`>
: neverGiven that the valid SELECT syntax we support would be SELECT {columns} FROM {table} we can leave this logic pretty simple and provide some meaningful errors when we run into an issue parsing. There are also some utilities to check for valid syntax on columns when parsing (don’t allow extra spaces for example) and we can use our SplitSQL to extract the columns using our familiar loops in the ParseColumns type to generate an array of references that we can project back into an object with the correct SelectedColumns type signature.
Strings As SQL Finally
Wow, that was a LOT, thanks so much for making it here and we now have the building blocks for expanding our parser quite a bit. There are still a lot of statement types, strange syntax and weird edge cases that we have to deal with before we call it done, but this is a huge step forward. As we move into the next articles, we’ll be taking a look at where we have gaps in our original goals that were outlined and work on filling them in, while also chipping away at some more fun syntax. I hope you’ve found some new tricks you can use with TypeScript and we’ll be back again soon to see what else we can make it do!
