Part 2 in our SQL Parsing Journey With TypeScript
Defining SQL Schemas For Parsing
Types and objects are both required
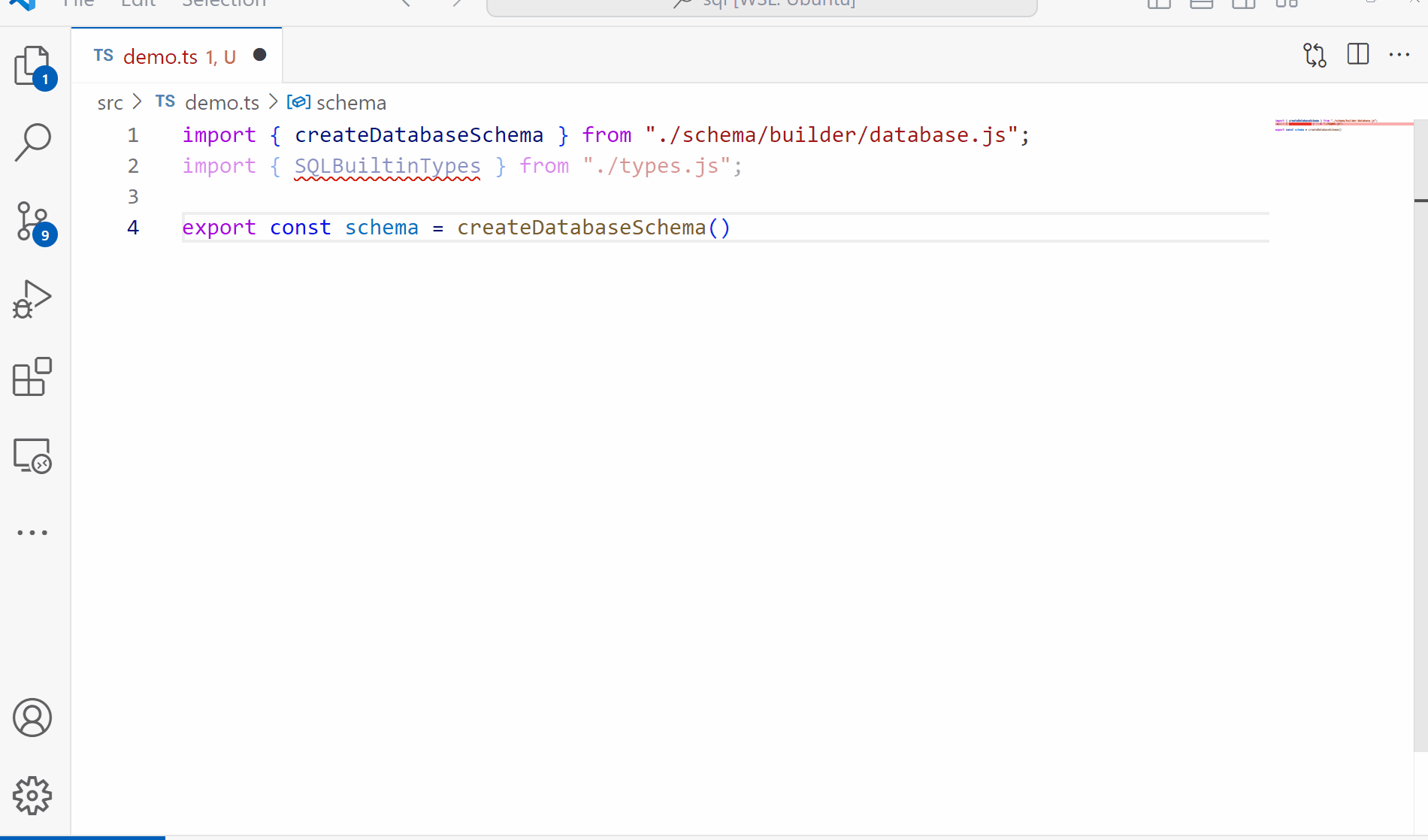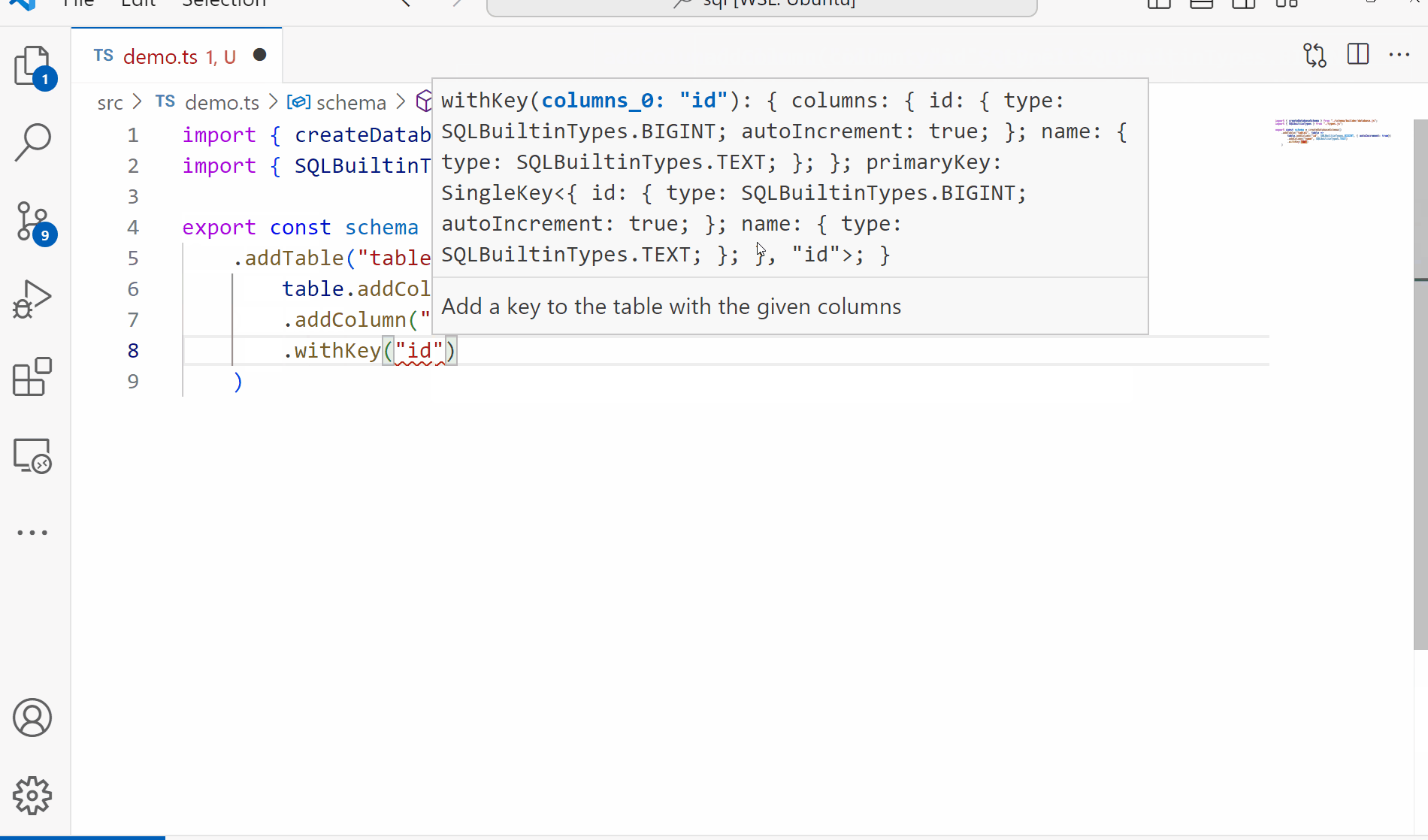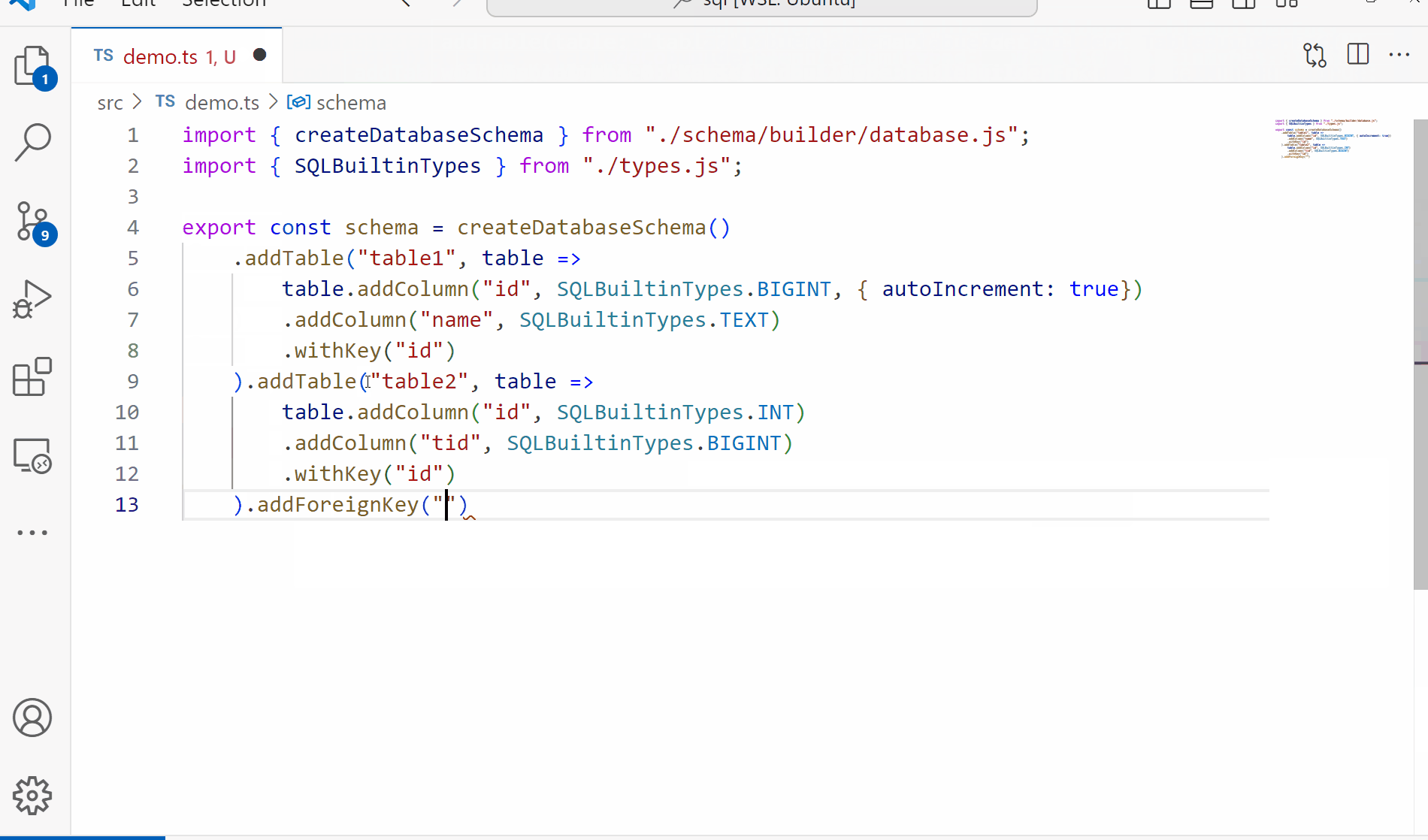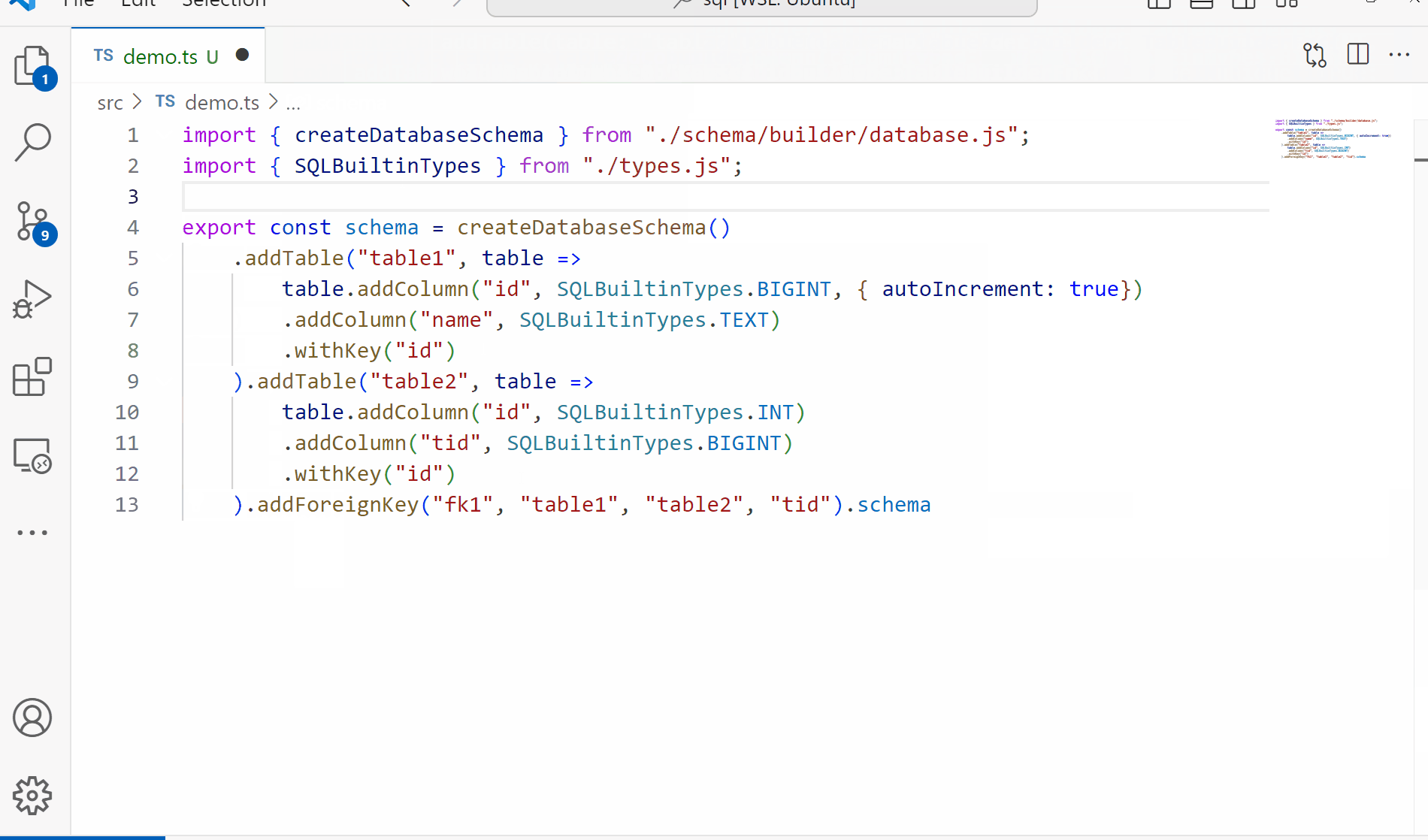
Welcome back to our exploration of what we can do with TypeScript as a language while trying to build a type safe, compile time SQL parser. In the first article we outlined some goals for ourselves and created some simple types for our AST and basic SQL structure. Since one of our goals for this project is to have a fully functioning parser and validator for our queries, we need something to validate against. Today we’ll be working on the schema building to produce something like the following:
You can find all the code we use for this article as well as others in the github repository below and there are branches for each of the articles in this series so you can follow along with the progress.
Database Schemas
One of the things that we touched upon briefly that is going to come back to make life fun is that every database provider does things just a little bit different when it comes to schemas. The different table options for storage, indexing, relationships, etc. can change wildly when you try to issue commands to the DBMS itself. What works in MySQL may not work in Postgres, which also may not work in SQL Server or Oracle later on.
Much like we did with the query AST for abstracting the main structures, the same principles can apply to our SQL schema. Even with the plethora of options available through different DBMS providers, there are a couple of solid foundations to build upon, namely tables and primary/foreign keys. We also mostly care about the general structure of a table, the columns available and some of the options that might come up for our query parsing.
Column Schemas
Since tables are built of columns, let’s begin our definitions at that level.
import type { Flatten, IgnoreAny } from "../type-utils/common.js"
import type {
IncrementalSQLTypes,
SQLBuiltinTypes,
TSSQLType,
VariableSQLTypes,
} from "../types.js"
/**
* Define a schema
*/
export type SQLColumnSchema = {
[key: string]: ColumnTypeDefinition<IgnoreAny>
}
/**
* The options for definitin a column
*/
export type SQLColumnOptions<T extends SQLBuiltinTypes> = Omit<
ColumnTypeDefinition<T>,
"type"
>
/**
* The type information for a column
*/
export type ColumnTypeDefinition<T extends SQLBuiltinTypes> = Flatten<
IncrementalType<T> & VariableType<T> & BaseColumnDefinition<T>
>
/**
* A value or provider of a value
*/
export type DefaultValueProvider<T extends SQLBuiltinTypes> =
| TSSQLType<T>
| (() => TSSQLType<T>)
/**
* A base type for all SQL Columns
*/
type BaseColumnDefinition<T extends SQLBuiltinTypes> = {
type: T
array?: true
nullable?: true
unique?: true
default?: DefaultValueProvider<T>
}
/**
* Extended information for incremental column types
*/
type IncrementalType<T extends SQLBuiltinTypes> = [T] extends [
IncrementalSQLTypes
]
? { autoIncrement?: true }
: object
/**
* Extended information for variable size column types
*/
type VariableType<T extends SQLBuiltinTypes> = [T] extends [VariableSQLTypes]
? { size?: number }
: objectWhile this is pretty short, it does have a couple of important things I picked up while working with this schema solution. First, you’ll see a type being imported called IgnoreAny (we’ll explore those other utility types shortly). Basically, there are several places now where we have to allow the type system to use any to stop further type checking. In our AST code, it was because we wanted to prevent the circular recursion checks which are expected and fine. In this case, it’s also exploiting the type check termination but for a different reason.
When trying to narrow a statement like T extends SQLColumnSchema the compiler will try to evaluate the type signature for SQLColumnSchema. While the keys being strings will work out fine, there are issues because the columns are generic objects of the type ColumnTypeDefinition<T>. The compiler can’t reason out what the T should be on the column types, so NOTHING will match unless we tell it any value is correct. Ideally we could just scope it to something that extends SQLBuiltinTypes but that doesn’t provide all of the possible options since some SQL types have an autoIncrement property while others don’t. There is no way for TypeScript to get those options unless we just let everything through.
At the end of the day this isn’t a huge deal, it just means we’ll have to make sure we add protections in other layers to ensure that our columns are valid when we build them. You may also note that we specify some of those properties as optional with true as the only valid value. This is honestly to cut down on the number of edge cases we have to handle long term with column SQL option parameters. I made a decision in the parser that anything that doesn’t explicitly specify an option (nullable: true) is by default the opposite (not-nullable) and call it a day. This will make schema to database materialization easier and just fits more cleanly into my mental model.
We are now also leveraging some conditional types and a utility called Flatten to build these troublesome ColumnTypeDefinition types. The goal here is to have properties that only exist for some of the SQL types we defined (i.e. incremental shouldn’t be on EVERY possible column) so we use the conditionals to check the type. Based on the intersection of our option types, the Flatten utility will condense everything down into a single new type for us. Given that we’re going to be leveraging some utility types a lot, now is a great time to explore them.
Utility Types
The utilities are broken down into two files, one that is more general purpose and the other for modifying objects. For the general file, we have the following definitions:
/**
* Simple type that returns itself
*/
type Identity<T> = T
/**
* Collapse the type definition into a single type
*
* @template T The complex type to flatten
*/
export type Flatten<T> = Identity<{ [K in keyof T]: T[K] }>
/**
* Utility type to track all places where are are intentionally using any to
* break things
*/
// eslint-disable-next-line @typescript-eslint/no-explicit-any
export type IgnoreAny = any
/**
* Utility type to track all places where are are intentionally using an empty definition
*/
// eslint-disable-next-line @typescript-eslint/ban-types
export type IgnoreEmpty = {}
/**
* Utility type to carry some invalid type information
*/
export type Invalid<Error> = Error | void | never
/**
* Utility type to define an object or array
*/
export type OneOrMore<T> = T | AtLeastOne<T>
/**
* Type to ensure spread operators have at least one element
*/
export type AtLeastOne<T> = [T, ...T[]]The Flatten and Identity types work together to construct a single, collapsed type as we start generating more and more complex type definitions. Since the type that we pass into Flatten might be unions, intersections or a bunch of type decorations otherwise merged together, they get very hard to read and can eventually start to cause issues for the compiler trying to reason through deeply nested chains. To get around this, we simple grab all of the keys that exist at some point in time and assign their values inside of a new single type that looks way more reasonable to the compiler and our IDE.
The IgnoreAny that we saw is there to track all the places where we’re intentionally bypassing TypeScript checking and keep the linting rules to ignore any to a minimum (same with IgnoreEmpty ). Next we have the Invalid type which we’ll pass around to detect type errors since TypeScript doesn’t yet have a good way to return back an error from the type system itself. Finally, we have two utility methods that simply allow either a single object or an array of the same type, and another that ensures an array contains at least one value for using in some spread functions.
For the object utilities, most of these types are for manipulating keys since we generally use strings but TypeScript by default says a property key is a string | number | symbol and there isn’t a way to change that. Record<string, T> still has string | number | symbol as the keyof signature…
import type { Flatten, Invalid } from "./common.js"
/**
* Get all the keys of type T
*/
export type Keys<T> = {
[K in keyof T]: K
}[keyof T]
/**
* Get all of the keys that are strings
*/
export type StringKeys<T> = Extract<Keys<T>, string>
/**
* Creates a type that has the required subset properties of T
*/
export type RequiredSubset<T, K extends keyof T> = Flatten<{
[k in K]-?: T[k]
}>
/**
* All of the literal required keys from a type
*/
export type RequiredLiteralKeys<T> = {
[K in keyof T as string extends K
? never
: number extends K
? never
: object extends Pick<T, K>
? never
: K]: T[K]
}
/**
* All of the optional (explicit) keys
*/
export type OptionalLiteralKeys<T> = {
[K in keyof T as string extends K
? never
: number extends K
? never
: object extends Pick<T, K>
? K
: never]: T[K]
}
/**
* Type guard to prevent duplicate keys
*/
export type CheckDuplicateKey<K extends string, T> = [K] extends [StringKeys<T>]
? Invalid<"Duplicate keys are not allowed">
: KThe two outliers to the keys only rule are:
RequiredSubsetThis type ensures that whatever new type is being defined has keys from the original and that all properties are required (removing optional flags).CheckDuplicateKeyThis type does exactly what it suggests, verifying that the key is not already defined on the type. If the key is already in use, it will return our newInvalidtype with an error message we can detect.
Tables and Keys
The last of our schema types are split into tables, the overall database structure and the keys.
import type { IgnoreAny } from "../type-utils/common.js"
import type { SQLColumnSchema } from "./columns.js"
import type { ForeignKey, PrimaryKey } from "./keys.js"
/**
* A table key
*/
export type SQLTableSchema<
Schema extends SQLColumnSchema = SQLColumnSchema,
Key extends PrimaryKey<Schema> = never
> = [Key] extends [never]
? {
columns: Schema
}
: {
columns: Schema
primaryKey: Key
}
/**
* The set of database tables
*/
export type SQLDatabaseTables = {
[key: string]: SQLTableSchema<IgnoreAny>
}
export type ForeignKeys = {
[key: string]: ForeignKey<IgnoreAny>
}
/**
* The entire database schema
*/
export type SQLDatabaseSchema<
Tables extends SQLDatabaseTables = SQLDatabaseTables,
Relations extends ForeignKeys = ForeignKeys
> = {
tables: Tables
relations: Relations
}There isn’t a whole lot going on here outside of a conditional property if a primary key is defined on a table. The keys are another story entirely as we finally get to start mixing around several different concepts that we saw previously in a much more interesting way.
import type { StringKeys } from "../type-utils/object.js"
import type { SQLBuiltinTypes } from "../types.js"
import type { SQLColumnSchema } from "./columns.js"
import type { SQLDatabaseTables, SQLTableSchema } from "./database.js"
/**
* Represents a type of primary key
*/
export type PrimaryKey<Schema extends SQLColumnSchema> =
| SingleKey<Schema, StringKeys<Schema>>
| CompositeKey<Schema, StringKeys<Schema>[]>
/**
* Represents a single column key
*/
export type SingleKey<
Schema extends SQLColumnSchema,
Column extends StringKeys<Schema>
> = {
column: Column
}
/**
* Represents a composite column key
*/
export type CompositeKey<
Schema extends SQLColumnSchema,
Columns extends StringKeys<Schema>[]
> = {
column: Columns
}
/**
* Find a columns that are a valid type match
*/
type ForeignKeyColumnMatch<
Table extends SQLColumnSchema,
ColumnType extends SQLBuiltinTypes
> = {
[Key in StringKeys<Table>]: Table[Key]["type"] extends ColumnType
? Table[Key]["nullable"] extends true
? never
: Key
: never
}[StringKeys<Table>]
/**
* Recursive type that extracts all of the valid columns for each column in the
* original table key
*/
type CompositeForeignKeyColumnMatch<
Table extends SQLColumnSchema,
Columns extends SQLBuiltinTypes[]
> = Columns extends [infer Next extends SQLBuiltinTypes, ...infer Rest]
? Rest extends never[]
? [ForeignKeyColumnMatch<Table, Next>]
: Rest extends SQLBuiltinTypes[]
? [
ForeignKeyColumnMatch<Table, Next>,
...CompositeForeignKeyColumnMatch<Table, Rest>
]
: never
: never
/**
* Recursive type to extract the column types in order for a given primary key
*/
type ExtractCompositeKeyTypes<
Table extends SQLColumnSchema,
Columns extends StringKeys<Table>[]
> = Columns extends [infer Column extends StringKeys<Table>, ...infer Rest]
? Rest extends never[]
? [Table[Column]["type"]]
: Rest extends StringKeys<Table>[]
? [Table[Column]["type"], ...ExtractCompositeKeyTypes<Table, Rest>]
: never
: never
/**
* Utility type to get the matching columns from a table given a primary key on
* the initial table
*/
export type ForeignKeyColumns<
Database extends SQLDatabaseTables,
Source extends ForeignKeyReferenceTables<Database>,
Destination extends StringKeys<Database>
> = GetPrimaryKey<Database[Source]> extends SingleKey<
Database[Source]["columns"],
infer Column extends StringKeys<Database[Source]["columns"]>
>
? [
ForeignKeyColumnMatch<
Database[Destination]["columns"],
Database[Source]["columns"][Column]["type"]
>
]
: GetPrimaryKey<Database[Source]> extends CompositeKey<
Database[Source]["columns"],
infer Columns extends StringKeys<Database[Source]["columns"]>[]
>
? CompositeForeignKeyColumnMatch<
Database[Destination]["columns"],
ExtractCompositeKeyTypes<Database[Source]["columns"], Columns>
>
: never
/**
* Get candidate tables that have a defined primary key
*/
export type ForeignKeyReferenceTables<Schema extends SQLDatabaseTables> = {
[Key in StringKeys<Schema>]: Schema[Key] extends SQLTableSchema<
infer TableSchema
>
? Schema[Key] extends SQLTableSchema<
TableSchema,
infer _ extends PrimaryKey<TableSchema>
>
? Key
: never
: never
}[StringKeys<Schema>]
/**
* Extract the primary key from a {@link SQLTableSchema}
*/
export type GetPrimaryKey<Schema extends SQLTableSchema> =
Schema extends SQLTableSchema<infer Columns>
? Schema extends SQLTableSchema<
Columns,
infer PK extends PrimaryKey<Columns>
>
? PK
: never
: never
/**
* Defines a foreign key
*/
export type ForeignKey<
Database extends SQLDatabaseTables,
Reference extends ForeignKeyReferenceTables<Database> = ForeignKeyReferenceTables<Database>,
Target extends StringKeys<Database> = StringKeys<Database>,
Columns extends ForeignKeyColumns<
Database,
Reference,
Target
> = ForeignKeyColumns<Database, Reference, Target>
> = {
reference: Reference
referenceColumns: GetPrimaryKey<Database[Reference]>["column"]
target: Target
targetColumns: Columns
}This took a couple of attempts to write correctly and I’m sure it still has some flaws that will get cleaned up later as I learn more or the language allows new syntax but I’ll try to explain what is going on.
Before getting too far into the types, we should examine what a primary or foreign key does as that influences a lot of the code. A key can have either a single column or a collection of columns that define it, however if we use a collection, the order MATTERS. [A, B] !== [B, A] when it comes to the key structure in most databases so we can’t just rely on a simple union of column names since A|B === B|A in the underlying TypeScript set manipulations. As we can see in the SingleKey and CompositeKey classes, that’s pretty easy to keep together since one takes a property key while the other takes an array of the keys which helps us preserve the order.
However, there is a catch here regarding the array. If we simply did something like Columns extends (infer T extends StringKeys<Schema>)[] this would give us a value of T that was a union of the properties which ignores the order. We actually need those individual columns in order because one of the other fun quirks is that a foreign key column has to be a matching type to the reference (you can’t say an INT references JSON for example). Since each of the columns can have a different type and foreign keys can be composite just like a primary key, we have to ensure the column types are correct at each location in the array.
Getting the types isn’t too bad though as we can now leverage conditionals and recursive types to extract those columns one by one. This is going to be a major building block going forward so we want to understand a few of the quirks of how it works. We’ll use a slightly simplified example for discussing everything.
Looping with Type evaluation
// Some type manipulation
type Modifier<T extends SomeType> = T
// Recursive structure
type RecursiveArrayModifier<T extends SomeType[]> = T extends [infer Next extends SomeType, ...infer Rest] ?
// Check if there is no more data since an empty spread is never[], NOT []
Rest extends never[] ? [Modifier<Next>] :
// Verify our Rest parameter meets the type criteria of our RecursiveArrayModifier
Rest extends SomeType[] ? [Modifier<Next>, ...RecursiveArrayModifier<Rest>] :
// This generally shouldn't happen
never
// This also shouldn't happen
: never
Given our RecursiveArrayModifier type, we are going to manipulate an array of SomeType and force T to extend that so we get correct type narrowing. We then perform a check to see if T has more than one element by splitting it into Next and using the spread syntax to collect the other elements into a placeholder named Rest. If Rest is empty we simply use our Modifier to do something to that last value and then return it back as an array. If we have more values in our Rest parameter however, we modify the current value and add it to the results of recursively calling our RecursiveArrayModifier to process the remaining elements.
Essentially, this let’s us manipulate the elements one at a time, much like a normal for loop with whatever transformational logic we want in our Modifier function. We could probably even make this a utility type, however getting all of the additional context we might need to pass along every time for the Modifier itself is a pain and the logic is simple enough that we can pattern it pretty well to keep our code semi readable. I might explore later going back to try to pack something into the type-utils package.
There is a cost worth pointing out in this strategy and that is each recursive “loop” through the types generates a new set of types the compiler tracks. As an illustration of what that means, imagine we have a type [Foo, Bar, Baz] . when we call the RecursiveArrayModifier to do something, it will generate the following types:
RecursiveArrayModifier<[Foo, Bar, Baz]>[Modified<Foo>, RecursiveArrayModifier<[Bar, Baz]>][Modified<Foo>, Modified<Bar>, RecursiveArrayModifier<[Baz]>][Modified<Foo>, Modified<Bar>, Modified<Baz>]
Depending on how complicated the Modified type is and the depth of the type array you are processing, the number of total types generated can be quite large (that sample generated 9 unique types as the array combinations are ALSO unique types).
Schema Building
That’s a lot of things so far and we haven’t touched the builders! They are a lot easier to deal with since they mostly leverage the types that we have already defined. There are still a few things to be careful about and we can see most of them in the database builder below:
import type { Flatten, IgnoreEmpty } from "../../type-utils/common.js"
import type { CheckDuplicateKey, StringKeys } from "../../type-utils/object.js"
import type {
ForeignKeys,
SQLDatabaseSchema,
SQLDatabaseTables,
SQLTableSchema,
} from "../database.js"
import type {
ForeignKey,
ForeignKeyColumns,
ForeignKeyReferenceTables,
} from "../keys.js"
import { createTableSchemaBuilder, type TableSchemaBuilder } from "./table.js"
/**
* Utility type for an empty schema
*/
type EmptyDatabaseSchema = SQLDatabaseSchema<IgnoreEmpty, IgnoreEmpty>
/**
* A function that provides a TableSchemaBuilder and returns the builder or schema
*/
type TableBuilderFn<Schema extends SQLTableSchema> = (
builder: TableSchemaBuilder
) => TableSchemaBuilder<Schema> | Schema
/**
* Utility type to add the table definition to a schema to prevent return type re-calculation
*/
type AddTableToBuilder<
TableSchema extends SQLTableSchema,
Table extends string,
Database extends SQLDatabaseSchema
> = DatabaseSchemaBuilder<AddTableToSchema<Database, Table, TableSchema>>
/**
* Utility type to add a table to an existing schema
*/
type AddTableToSchema<
Database extends SQLDatabaseSchema,
Table extends string,
TableSchema extends SQLTableSchema
> = Database extends SQLDatabaseSchema<infer Tables, infer Relations>
? Relations extends ForeignKeys
? CheckSQLDatabaseSchema<
Flatten<Tables & { [key in Table]: TableSchema }>,
Relations
>
: never
: never
/**
* Utililty type to add a foreign key to a schema
*/
type AddForeignKeyToSchema<
Database extends SQLDatabaseSchema,
Name extends string,
FK
> = Database extends SQLDatabaseSchema<infer Tables, infer Keys>
? FK extends ForeignKey<
Tables,
infer Source,
infer Destination,
infer Columns
>
? SQLDatabaseSchema<
Tables,
Flatten<
Keys & {
[key in Name]: ForeignKey<Tables, Source, Destination, Columns>
}
>
>
: never
: never
/**
* Type to narrow types to SQLDatabaseSchemas
*/
type CheckSQLDatabaseSchema<Tables, Relations> =
Tables extends SQLDatabaseTables
? Relations extends ForeignKeys
? SQLDatabaseSchema<Tables, Relations>
: never
: never
/**
* Create a {@link DatabaseSchemaBuilder} from an existing schema or start an
* empty one
*
* @param current The current schema if it exists
* @returns A {@link DatabaseSchemaBuilder}
*/
export function createDatabaseSchema<
Schema extends SQLDatabaseSchema = EmptyDatabaseSchema
>(current?: Schema): DatabaseSchemaBuilder<Schema> {
return new SQLDatabaseSchemaBuilder(current)
}
/**
* An object that provides a SQLDatabaseSchema
*/
export interface DatabaseSchemaBuilder<Schema extends SQLDatabaseSchema> {
readonly schema: Schema
/**
* Add a table to the database schema
*
* @param table The table to add
* @param builder The Table builder function to use for the definition
*/
addTable<Table extends string, TableSchema extends SQLTableSchema>(
table: CheckDuplicateKey<Table, Schema["tables"]>,
builder: TableBuilderFn<TableSchema>
): AddTableToBuilder<TableSchema, Table, Schema>
/**
* Create a foreign key given between the source and destination tables with
* the given name
*
* @param name The name of the foreign key
* @param reference The reference table for the key
* @param target The target table for the key
* @param column The columns from the destination that match the source
* primary key
*/
addForeignKey<
Name extends string,
Reference extends ForeignKeyReferenceTables<Schema["tables"]>,
Target extends StringKeys<Schema["tables"]>,
Columns extends ForeignKeyColumns<Schema["tables"], Reference, Target>
>(
name: CheckDuplicateKey<Name, Schema["relations"]>,
reference: Reference,
target: Target,
...column: Columns
): DatabaseSchemaBuilder<
AddForeignKeyToSchema<
Schema,
Name,
ForeignKey<Schema["tables"], Reference, Target, Columns>
>
>
}
/**
* Default implementation of the {@link DatabaseSchemaBuilder}
*/
class SQLDatabaseSchemaBuilder<Schema extends SQLDatabaseSchema>
implements DatabaseSchemaBuilder<Schema>
{
private _schema: unknown
constructor(schema?: Schema) {
this._schema = schema ?? { tables: {}, relations: [] }
}
get schema(): Schema {
return this._schema as Schema
}
addTable<Table extends string, TableSchema extends SQLTableSchema>(
table: CheckDuplicateKey<Table, Schema["tables"]>,
builder: TableBuilderFn<TableSchema>
): AddTableToBuilder<TableSchema, Table, Schema> {
const result = builder(createTableSchemaBuilder())
const schema = "schema" in result ? result["schema"] : result
const current = this._schema as Schema
Object.defineProperty(current.tables, table as string, {
configurable: false,
enumerable: true,
writable: false,
value: schema,
})
return this as unknown as AddTableToBuilder<TableSchema, Table, Schema>
}
private _getTableKey(table: object): unknown {
return "primaryKey" in table &&
typeof table.primaryKey === "object" &&
table.primaryKey !== null &&
"column" in table.primaryKey
? Array.isArray(table.primaryKey.column)
? table.primaryKey.column
: [table.primaryKey.column]
: []
}
addForeignKey<
Name extends string,
Reference extends ForeignKeyReferenceTables<Schema["tables"]>,
Target extends StringKeys<Schema["tables"]>,
Columns extends ForeignKeyColumns<Schema["tables"], Reference, Target>
>(
name: CheckDuplicateKey<Name, Schema["relations"]>,
reference: Reference,
target: Target,
...column: Columns
): DatabaseSchemaBuilder<
AddForeignKeyToSchema<
Schema,
Name,
ForeignKey<Schema["tables"], Reference, Target, Columns>
>
> {
const current = this._schema as Schema
Object.defineProperty(current.relations, name as string, {
configurable: false,
enumerable: true,
writable: false,
value: {
reference,
referenceColumns: this._getTableKey(current.tables[reference]),
target,
targetColumns: column,
},
})
return this as unknown as DatabaseSchemaBuilder<
AddForeignKeyToSchema<
Schema,
Name,
ForeignKey<Schema["tables"], Reference, Target, Columns>
>
>
}
}As with some of the other code, there are several utility types (not exported) which are used for manipulating the Schema types we created before. Given that we are adding keys and tables to schemas with names, the main things to note are that parameters for the addTable or addForeignKey methods both have a signature for the name like:
name: CheckDuplicateKey<Name, Schema["relations"]>,This prevents duplicates from being added so we aren’t overwriting anything. The beauty of our Invalid type in this case is that whatever string was passed isn’t likely to match up with our error message, so the compiler will flag it as an error and highlight the problem for us.


In the builders, we can see that the individual class fields are all marked as unknown. Since the type is always being mutated, trying to keep this field as a typed value means we have to re-create objects constantly and jump through a bunch of hoops. However, we already know the object is valid because we built it with type constraints on the functions which keeping the data in sync for us. Given that, we go the completely unsafe route of saying “let’s cast this every time we return it and hope that we never mess it up”.
One last thing to take a look at where we’re leveraging TypeScript to keep our input correct is in the table building. The following snippet is in the both the ColumnSchemaBuilder and TableSchemaBuilder classes and generally is doing the same thing with the Options type:
addColumn<
Column extends string,
ColumnType extends SQLBuiltinTypes,
Options extends keyof SQLColumnOptions<ColumnType> = never
>(
column: CheckDuplicateKey<Column, Schema>,
type: ColumnType,
options?: RequiredSubset<SQLColumnOptions<ColumnType>, Options>
)This is actually some fun magic that allows us to greatly narrow down the types of columns that we produce using that utility RequiredSubset type we came across before.

Given the SQLColumnOptions for the given ColumnType, there may be some variable properties that only exist on certain columns. Because we are limiting the Options to only valid keywords for the specific ColumnType, we can quickly enforce that if someone wants to mark something as autoIncrement or nullable for instance, they can do so only for valid types. They also have to pass them as required (true per our earlier decision to be explicit or assumed behavior) which then lets us use this quick utility type:
type FinalColumnDefinition<
T extends SQLBuiltinTypes,
K extends keyof SQLColumnOptions<T>
> = Flatten<
RequiredLiteralKeys<ColumnTypeDefinition<T>> &
RequiredSubset<SQLColumnOptions<T>, K>
>This flattens the column to ONLY be able to have the options specified and nothing else, giving us type errors if you assign something with extra fields or values that aren’t true for example (or a different size for variable fields). It also has an added benefit of making our types easier to read without having a bunch of extra optional properties that will never be there included, all while maintaining our type safety.
Next Steps: Queries
This is already a LOT of content, thanks for taking the time to skim or read all the way through it and the code is all in github to explore below:
In the next article in this series, we’ll move along to use our schemas to start defining some actual queries and leverage the AST we built in the first part. Feel free to message me with questions (or suggestions to make things even better) and I hope this has helped you get a bit more into TypeScript and what you can do with it!
